
(ubuntu 22.04LTS版)
Windows版のC言語編に引き続き、ubuntu版のC言語編もやってみたいと思います。ubuntuはLinux/debian系オペレーティングシステムですから、もともとC言語とは大変相性が良いことは言うまでもありません。それに加えて、UTF-8というUNICODEのエンコーディング方式を利用できますので、日本語カスタマイザーだけではなく、他の外国語でも同じようにカスタマイザーを作成できるはずです。
ubuntu-OSもバージョンによって正式なサポート期間が決まっていて、現在ubuntu 22.04LTS(本家公式版)では2027年の4月までサポート予定です。22.04LTS版ではUbuntuの64ビットOSとして以下の練習問題の動作確認を行っています。
C言語の処理系は、ubuntu22.04.1されている下記9.3.0バージョンのgccを利用しました。C言語の処理系がない場合には、build-essentialパッケージをインスールしてC言語処理系(gcc)が使えるようにしておきます。
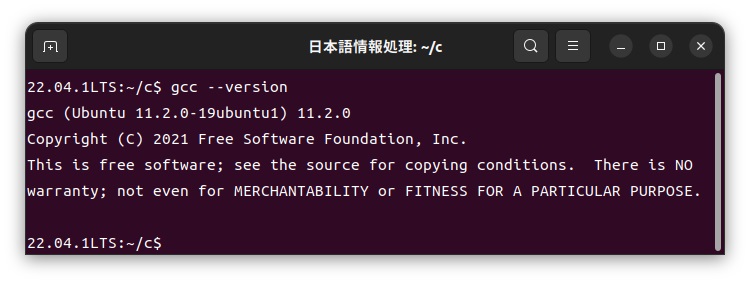
日本語カスタマイザーの使用例は、Windows版の各言語編でも述べていますので、詳しいことはそちらをご覧ください。まず、ubuntu版とWindows版での違いは、ubuntu版ではコマンド名の頭に「./」を付けます。
日本語カスタマイザーのシェルコマンドを「jcc」、日本語で書かれたC言語ファイルの名前を仮に「ファイル1.jc」とすると
$./jcc ファイル1
というシェルコマンド(バッチコマンド)によりファイル1.cを生成し、さらに翻訳(コンパイル)、結合(リンク)して、実行可能形式ファイルであるファイル1を生成します。そして生成されたプログラムを実行する場合には、次のように実行ファイル名の頭に「./」を付けて以下のように入力します。
$./ファイル1

実際のC言語プログラムでの応用例
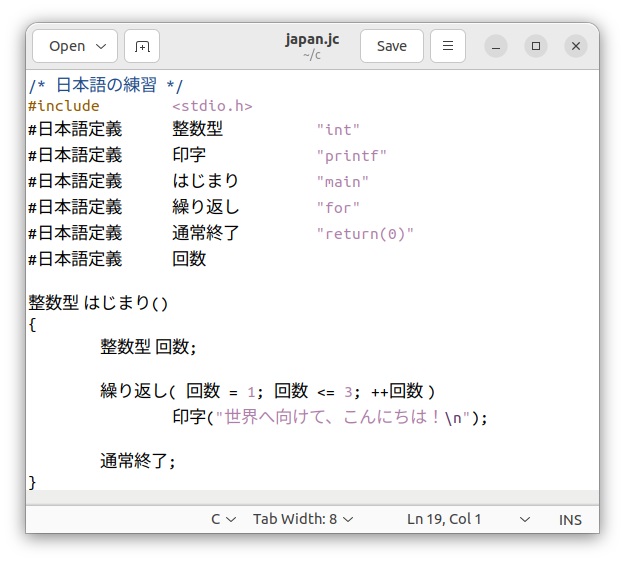
UTF-8での日本語文字はCJK統合漢字領域(Cは中国のChinese、Jは日本のJapanese、Kは韓国のKoreanの頭文字)を使用するのが一般的のようです。日本語カスタマイザーでもこの文字コード領域(Flex編での文字コード領域にハングル文字用コードを加えたもの)を利用しています。練習として、次のような日本語Cプログラム「japan.jc」を用意します。
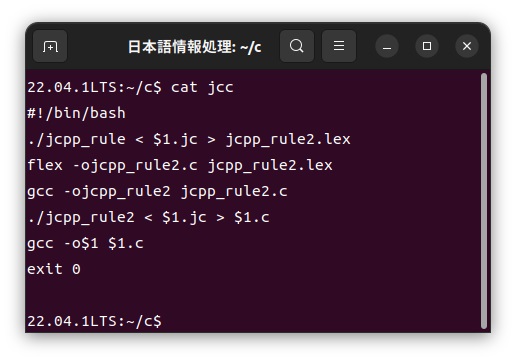
日本語カスタマイザーjccの中身は以下のような簡単なシェルスクリプトで構成されています(簡単化のためシェルスクリプト内のエラー処理は特にやっていませんが、エラーメッセージは出力されます)。jcpp_ruleというのがカスタマイザーの1パス目の実行プログラムで、jcpp_rule2というのが2パス目の実行プログラムです。
上記の「japan.jc」ファイルをカスタマイザーjccを使って、次のように通常のC言語である「japan.c」ファイルに展開し、このファイルをコンパイルして実行します。
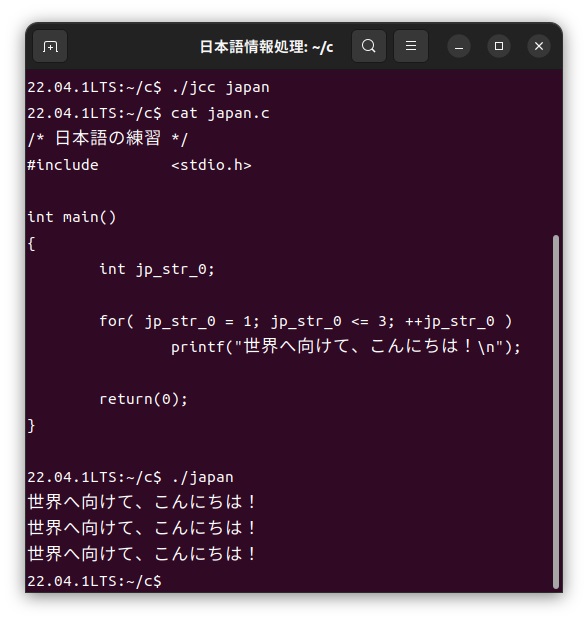
このようにubuntu版でもwindows版と同様に日本語カスタマイザーが動作することが分かります。
日本語と同じように中国語文字はCJK統合漢字領域を使用して、カスタマイザーを作成します。練習として、次のような中国語(簡体字)Cプログラムを用意します。
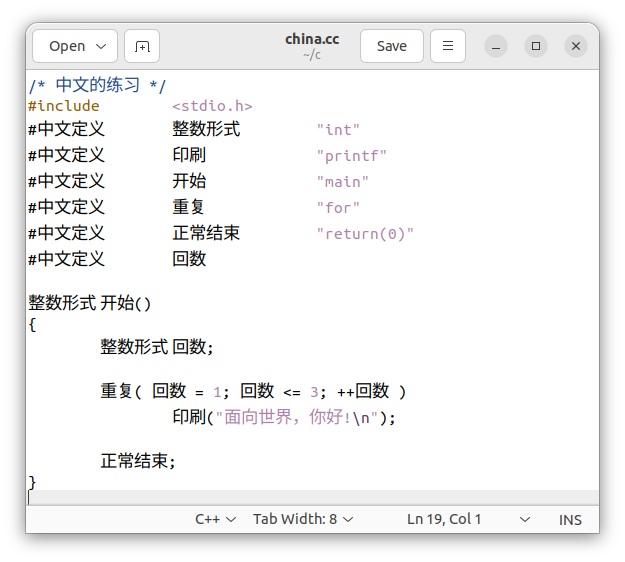
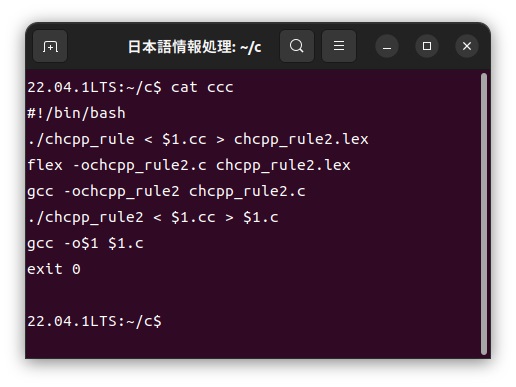
中国語カスタマイザーcccの中身は以下のような簡単なシェルスクリプトで構成されています。
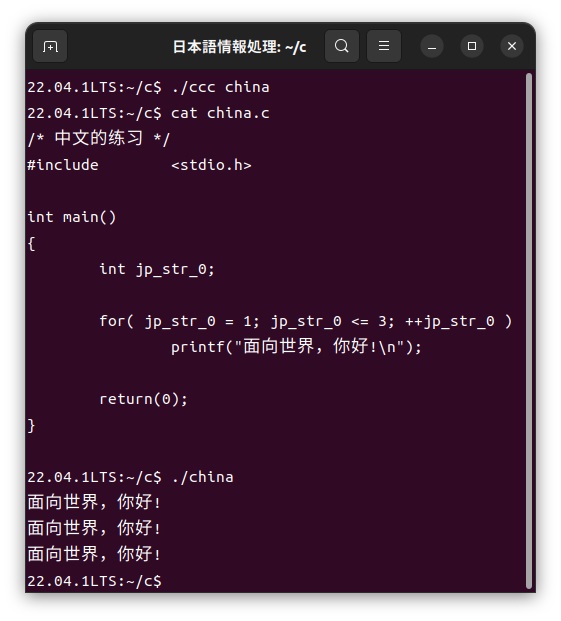
上記の「china.cc」ファイルをカスタマイザーを使って、次のように通常のC言語である「china.c」ファイルに展開し、このファイルをコンパイルして実行します。
日本語、中国語と同じように韓国語文字もCJK統合漢字領域を使用して、カスタマイザーを作成します。練習として、次のような韓国語Cプログラムを用意します。
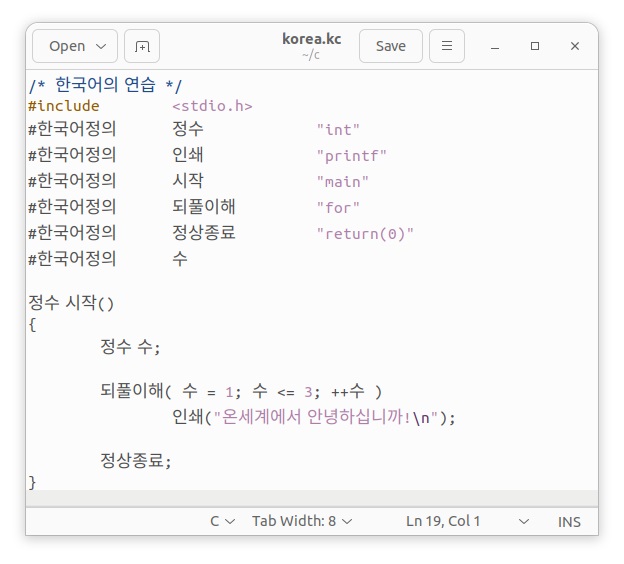
韓国語カスタマイザーkccの中身は以下のような簡単なシェルスクリプトで構成されています。
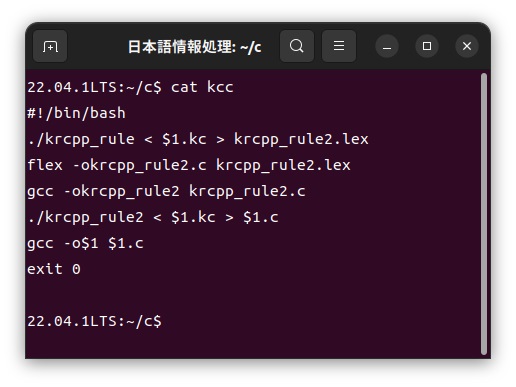
この「korea.kc」ファイルをカスタマイザーを使って、次のように通常のC言語である「korea.c」ファイルに展開し、このファイルをコンパイルして実行します。
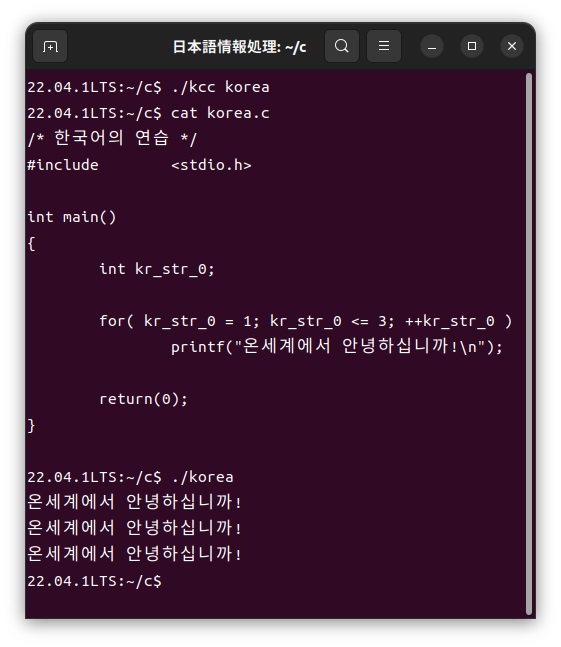
CJK統合漢字は、中国、日本、韓国で共通の文字コードとして策定されたものですが、文字だけをみると漢字は中国から伝来された文字ですので、日本人が見て分かる漢字文字がいくつもあるのではないでしょうか。
一方、現在韓国で使用されているハングル文字は、15世紀中ごろまで母国固有文字がなかった朝鮮半島で、はじめて国家事業として策定された文字体系ということで、日本や中国で使用されている漢字とは全く異なる文字体系に見えます。
ハングルは、母音と子音を組み合わせて音を表記するという特徴がありますので、漢字よりもむしろ日本の神代文字のような印象を受けます。
日本、中国、韓国といえば、東アジアでは古くから相互に歴史的な影響を及ぼし合ってきました。第二次世界大戦後、世界は先進国を中心に平和外交を旨として、文化、スポーツなどの交流が盛んになり、世界的な理想世界の建設を進めている今日からみますと、過去に戦乱の世で起こった蒙古襲来や朝鮮出兵などは、想像もできないことかもしれません。
特に中世、豊臣秀吉公の朝鮮出兵について、どうみるかということは現在でも多くの歴史家が持論を展開しています。
このころは、まだ英国から清教徒が北米に渡る以前の話ですが、日本では戦国時代といわれ、電気も蒸気機関も電波による通信手段もない昔のことです。武士が権力を持っていた封建時代でもありました。秀吉公は尾張の農民出身でしたが、織田信長公のもとで頭角を表し、水攻め、兵糧攻めなど天才的な戦のやり方で連戦連勝を続け ました。本能寺の変で信長公が討たれた後は、戦乱の世を平定、天下統一を果たして、ついに天皇の代理人といわれる関白にまで昇られた奇跡の人として知られております。
その秀吉公が朝鮮へ出兵したことが、世界史上どのような結果を招いたかというと、このことが引き金となって朝鮮に援軍を送っていた明(中国)が、戦費拡大のため国力を消耗し、明の滅亡につながるわけです。そしてこれが次の政権である清の出現を助けたことにもなったということではないでしょうか。秀吉公自身は、朝鮮出兵の最中に亡くなっています。
また、清の時代、中国歴史上、最高の指導者といわれる第四代の康煕(こうき)帝を出現させる原動力ともなったと考えられます。康煕帝は中国全土を平定し、さらに朝鮮までも清の属国としたため、少なくともその後、日本の徳川政権下においては外国からの侵入もなく、比較的長期政権が続いたのではないかと考えられます。
この時代、清では康煕事典をはじめとする、文化、芸術が非常によく発達したことは特筆すべきことだと思います。また、日本でも同じように元禄文化が華を開き、尾形光琳をはじめとして、日本絵画の巨匠達を多く生み出した時代でもありました。
私も中世の戦争行為自体を肯定するなどということは全くありませんが、世界史的な観点で後世のわれわれがこの時代を眺めますと、豊臣秀吉公の朝鮮出兵は、結果的に東アジアの長期安定政策の上で、決して 無益な殺生を行わせたものではなかったとみております。
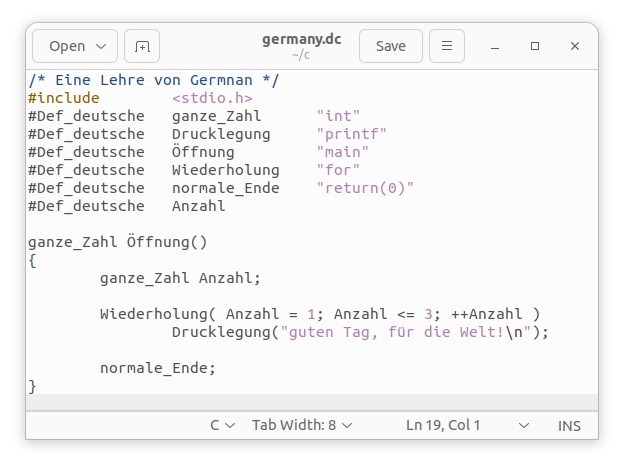
ドイツ語はラテンアルファベット26文字に加えて、「ÄÖÜ」などのウムラウト記号を含む文字や、 「ß」のエスツェットと呼ばれる文字が利用できるようにカスタマイザーを作成します。練習として、次のようにドイツ語Cプログラムを用意します。拡張子が「.dc」ファイルではgeditを直接起動できない場合には、アプリケーションの選択画面でgeditを起動してください。
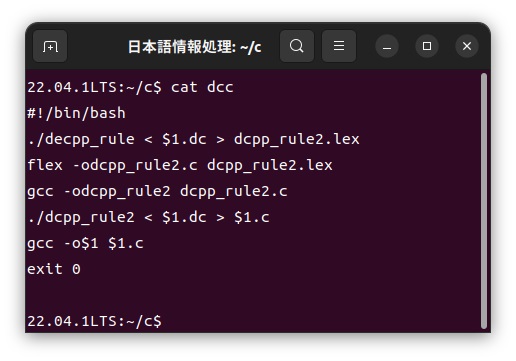
ドイツ語カスタマイザーdccの中身は以下のような簡単なシェルスクリプトで構成されています。
この「germany.dc」ファイルをカスタマイザーを使って、次のように通常のC言語である「germany.c」ファイルに展開し、このファイルをコンパイルして実行します。
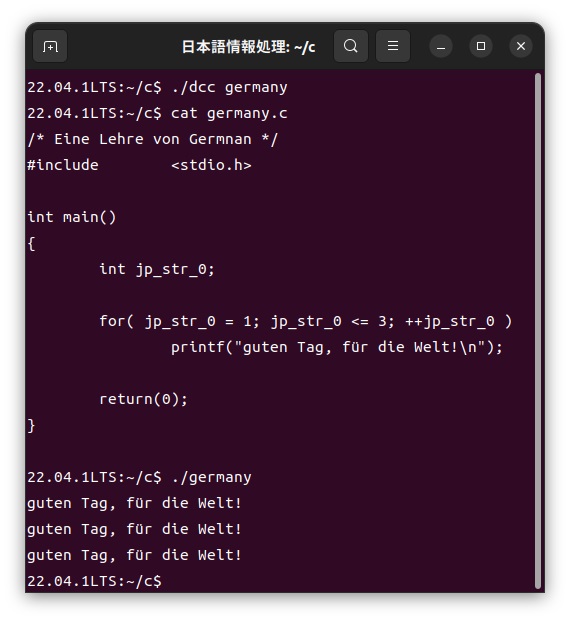
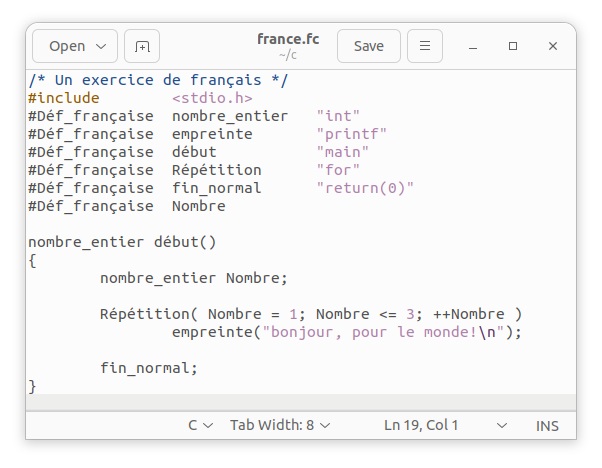
フランス語はラテンアルファベット26文字に加えて、「´」アキュート、「`」グレイヴ、「^」サーカムフレックスなどのアクセント符号や、「¨」トレマ、「Ç」セディーユ、「Œ」合字などが利用できるようにカスタマイザーを作成します。練習として、次のようにフランス語Cプログラムを用意します。
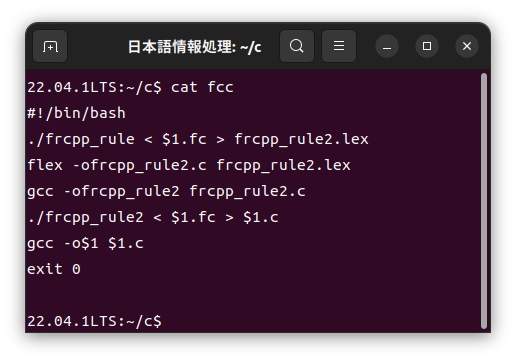
フランス語カスタマイザーfccの中身は以下のような簡単なシェルスクリプトで構成されています。
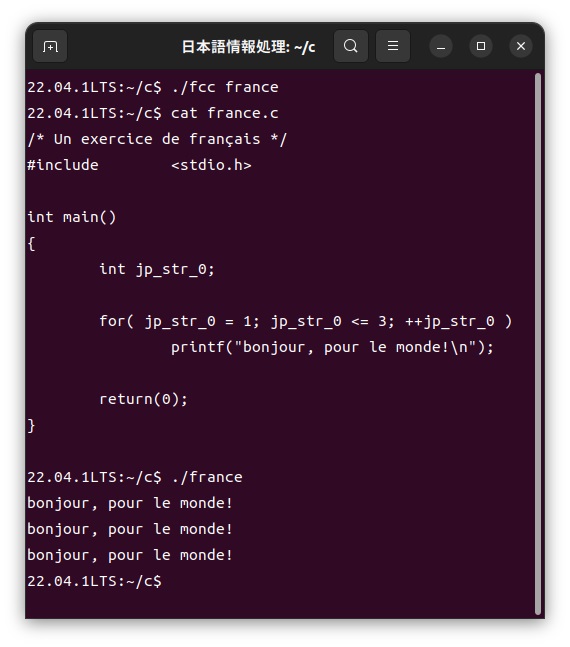
この「france.fc」ファイルをカスタマイザーを使って、次のように通常のC言語である「france.c」ファイルに展開し、このファイルをコンパイルして実行します。
イタリア語はラテンアルファベット26文字に加えて、母音のEとOが「´」アキュート、「`」グレイヴの両方のアクセント符号を持つそうです。それ以外の母音である 「AIU」はアキュートアクセント符号だけのようですので、これらの文字が利用できるようにカスタマイザーを作成します。練習として、次のようにイタリア語Cプログラムを用意します。
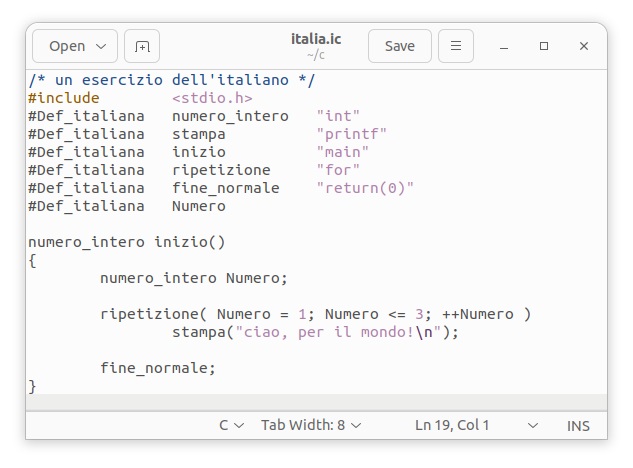
イタリア語カスタマイザーfccの中身は以下のような簡単なシェルスクリプトで構成されています。
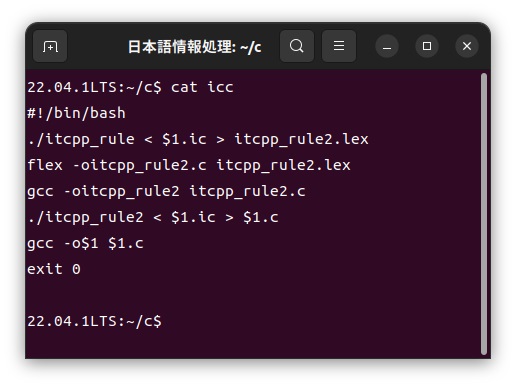
この「italia.ic」ファイルをカスタマイザーを使って、次のように通常のC言語である「italia.c」ファイルに展開し、このファイルをコンパイルして実行します。
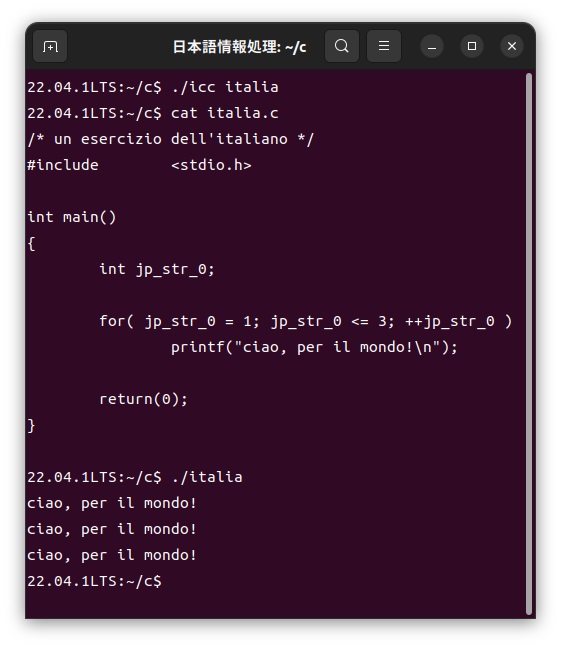
ポルトガル語はラテンアルファベット26文字に加えて、「´」アキュート、「`」グレイヴ、「^」サーカムフレックスのアクセント符号、「ÃÕ」の鼻母音記号、「¨」トレマ、「Ç」セディーユなどの文字が利用できるようにカスタマイザーを作成します。練習として、次のようにポルトガル語Cプログラムを用意します。
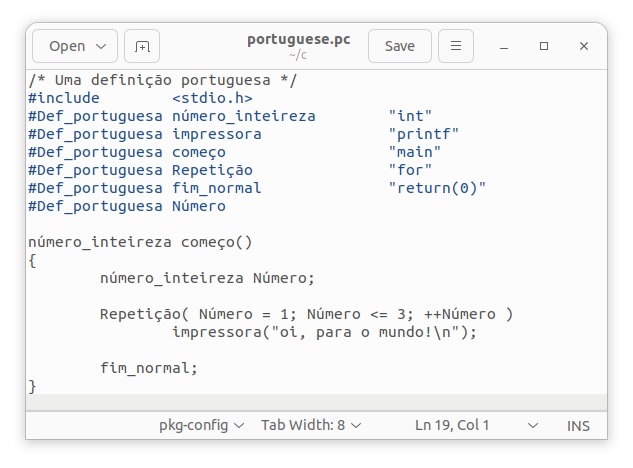
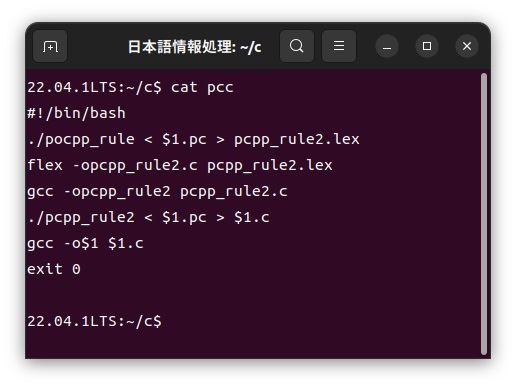
ポルトガル語カスタマイザーpccの中身は以下のような簡単なシェルスクリプトで構成されています。
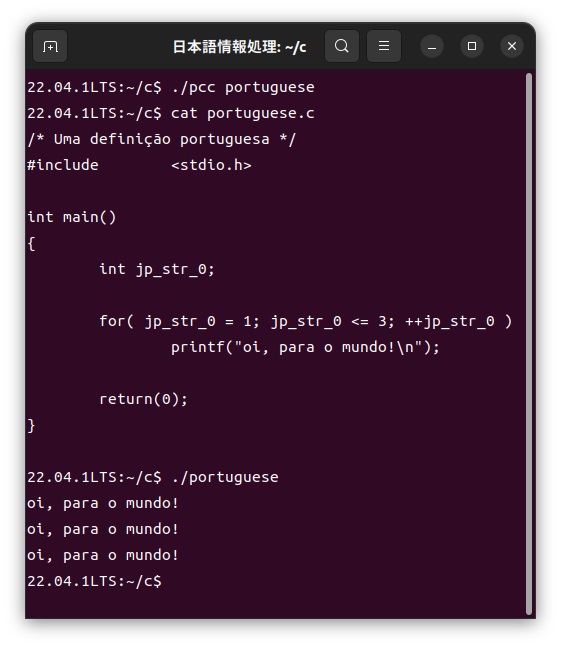
この「portuguese.pc」ファイルをカスタマイザーを使って、次のように通常のC言語である「portuguese.c」ファイルに展開し、このファイルをコンパイルして実行します。
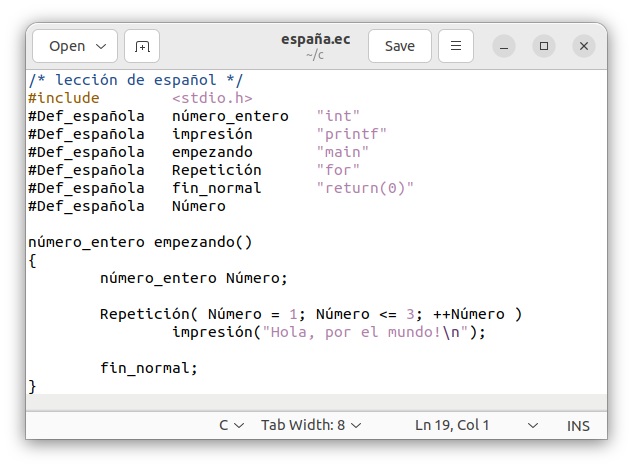
スペイン語はラテンアルファベット26文字に加えて、「Ñ」の鼻音記号、母音の「´」アキュートアクセント符号、「¨」トレマ、「¿」倒置疑問符、「¡」倒置感嘆符などの文字が利用できるようにカスタマイザーを作成します。練習として、次のようにスペイン語Cプログラムを用意します。
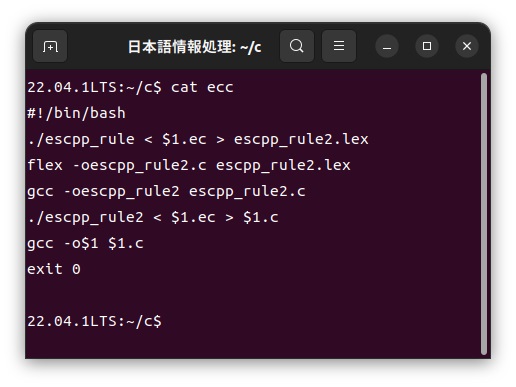
スペイン語カスタマイザーeccの中身は以下のような簡単なシェルスクリプトで構成されています。
この「españa.ec」ファイルをカスタマイザーを使って、次のように通常のC言語である「españa.c」ファイルに展開し、このファイルをコンパイルして実行します。ここで現在の入力環境は、「ñ」の鼻音記号などは直接キーボードから入力できないので、今回はエディターのGEDITからコピーした文字列をコマンド入力時にペーストして実行しました。
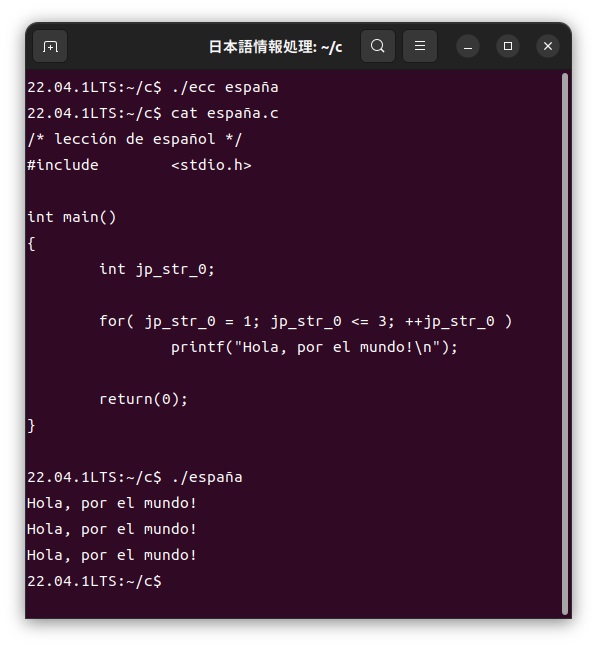
最近よくこのサイトもロシアからのアクセスがあるようですので、ロシア語でもやってみたいと思います。ロシア語のアルファベットは、キリル文字の一部だそうですが、UTF-8コードの中で定義されているロシア語アルファベットの大文字、子文字合わせて66文字が利用できるようにカスタマイザーを作成します。練習として、次のようにロシア語Cプログラムを用意します。
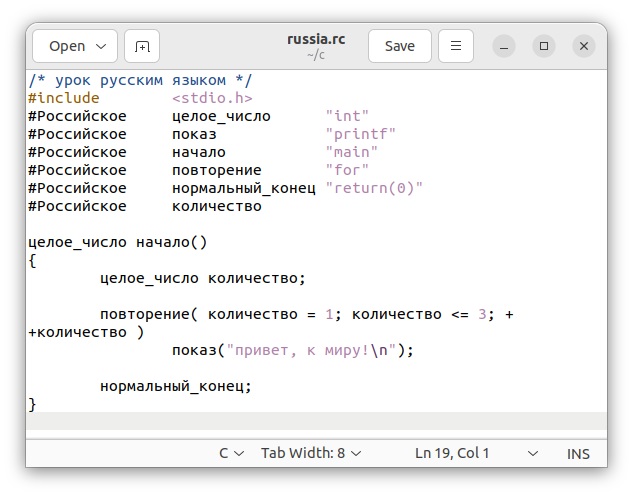
ロシア語カスタマイザーrccの中身は以下のような簡単なシェルスクリプトで構成されています。
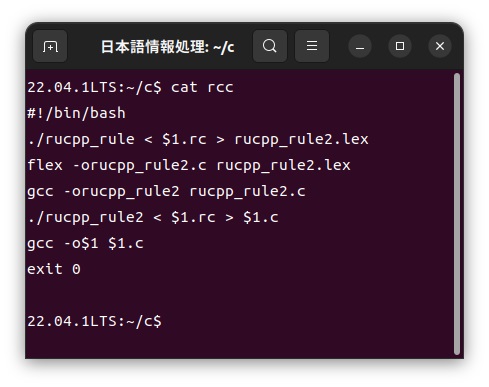
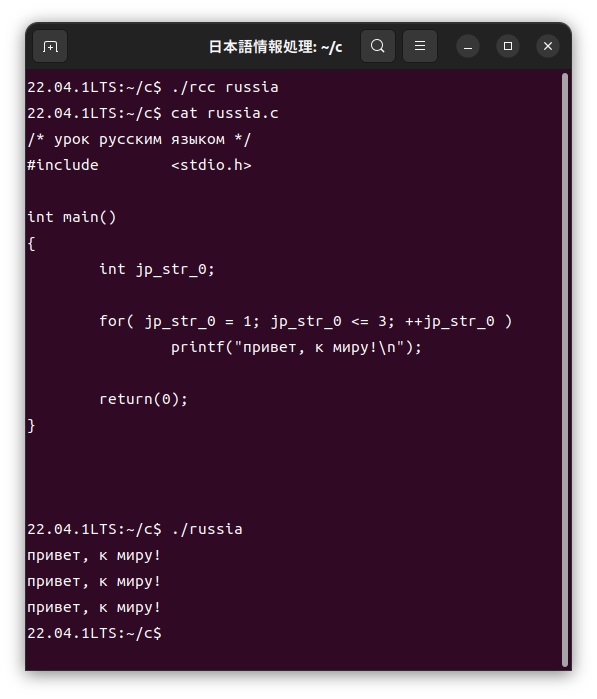
この「russia.rc」ファイルをカスタマイザーを使って、次のように通常のC言語である「russia.c」ファイルに展開し、このファイルをコンパイルして実行します。
インドの連邦公用語はヒンディー語(人口の約35%が話者)で、文字としてはデーヴァナーガリー文字を用いることを憲法で規定しています。また、準公用語は英語ですので、英語を理解するインド人は多数いるのではないかと推察します。インドでは、ヒンディー語の他に多数の言語が使われているそうです。(例えばベンガル語、テルグ語、マラーティー語、タミル語、ウルドゥー語、グジャラート語、マラヤーラム語、カンナダ語、オリヤー語、パンジャーブ語、ビハール語、ラージャスターン語、アッサム語、ビリー語、サンタル語、カシミール語など) ここでは、ヒンディー語のデーヴァナーガリー文字に対するUTF-8コードを使って、インド語Cプログラムを用意します。
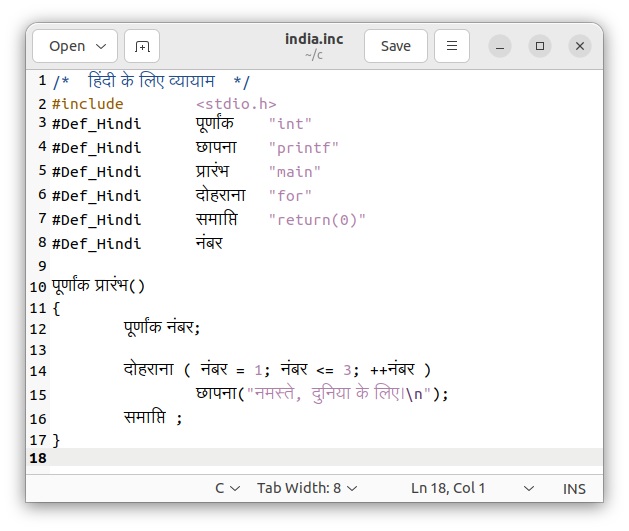
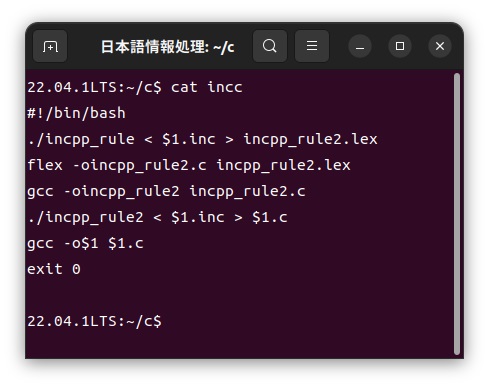
インド語カスタマイザーinccの中身は以下のような簡単なシェルスクリプトで構成されています。
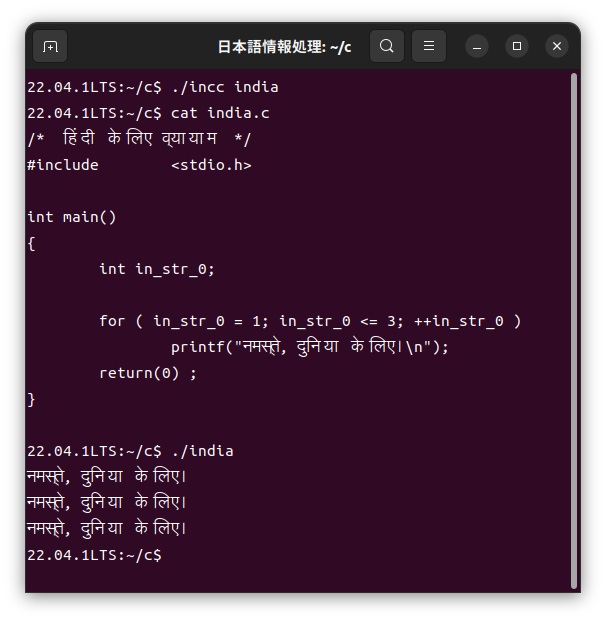
この「india.inc」ファイルをカスタマイザーを使って、次のように通常のC言語である「india.c」ファイルに展開し、このファイルをコンパイルして実行します。


参考図書
オートマトン・言語理論 本多波雄著 コロナ社 1972
UNIXプログラミング環境 Brian W.Kernighan Rob Pike 石田晴久監訳 アスキー出版局 1985
プログラミング言語C B.W. カーニハン D.M. リッチー 石田晴久訳 共立出版社 1981
UNIX 石田晴久著 共立出版社 1983
yacc/lex 五川女健治著 啓学出版社 1992
flex, version2.5 A Fast Scannar Generator ドキュメント University of California. Vern Paxsonほか多数のAuthor編著
ubuntu ドキュメント
世界史(改訂) 東京書籍株式会社 1979