


このサイトのテーマでもある「プログラム言語で日本語を多めに」という内容について、最初に公式の場で講演したときのスライドを以下に掲載します。これは2010年3月16日に宮崎大学で行なわれた「情報処理学会 火の国シンポジウム2010」のときのものです。


[注]日本語の文字は応神天皇の時代に漢字が伝わり、その後、片仮名文字が生まれ、続いて平安時代までに平仮名が誕生してきたということです。


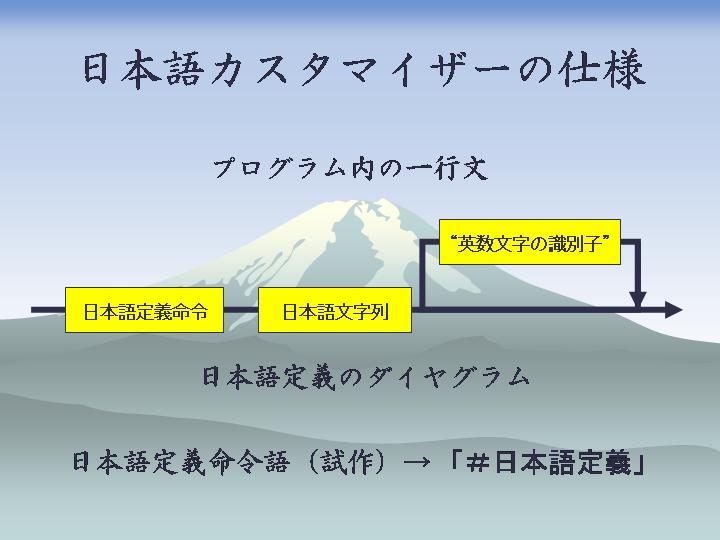
[注]情報処理記号については、学会発表時と多少変わっているものもあります。
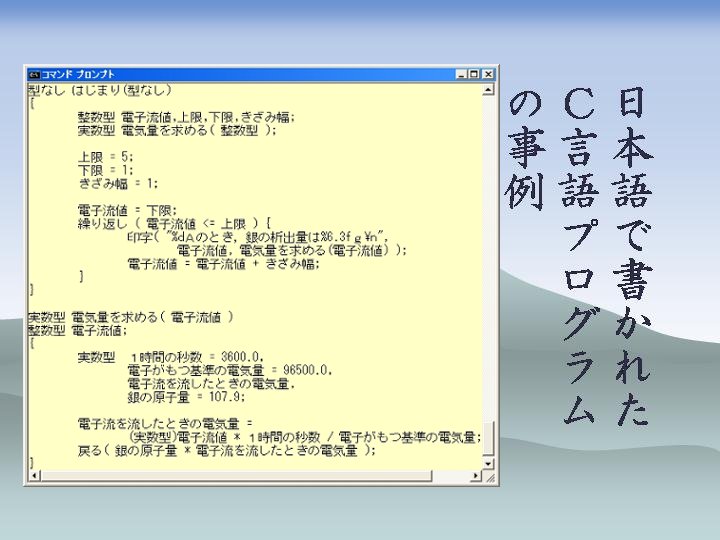
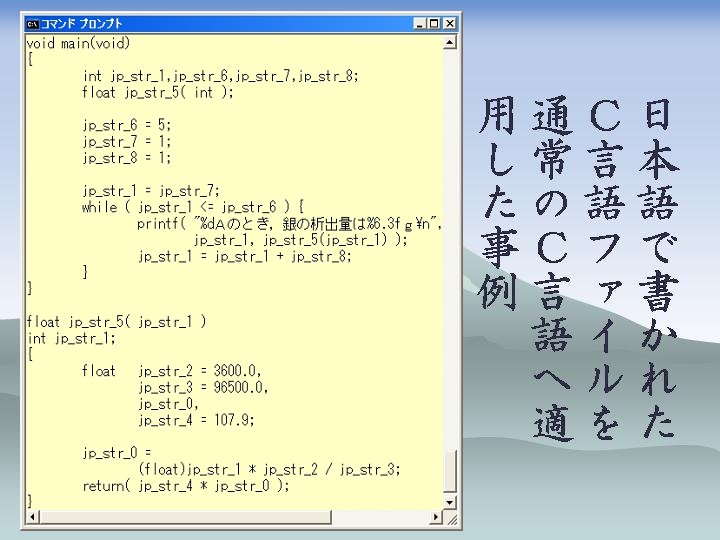
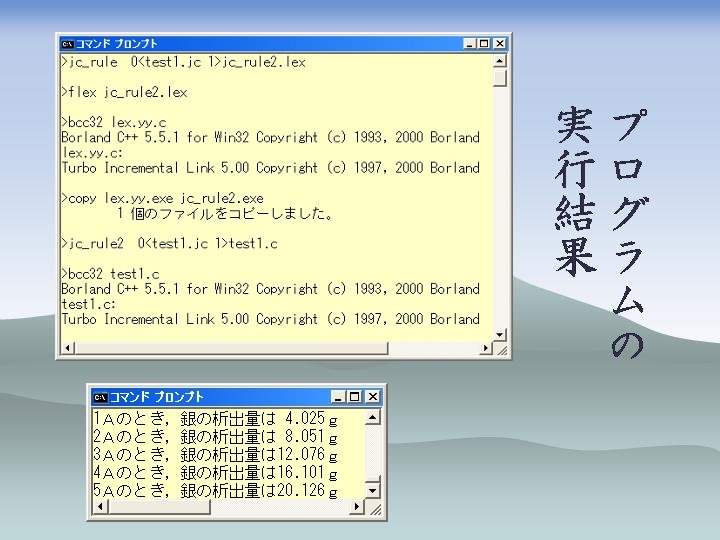


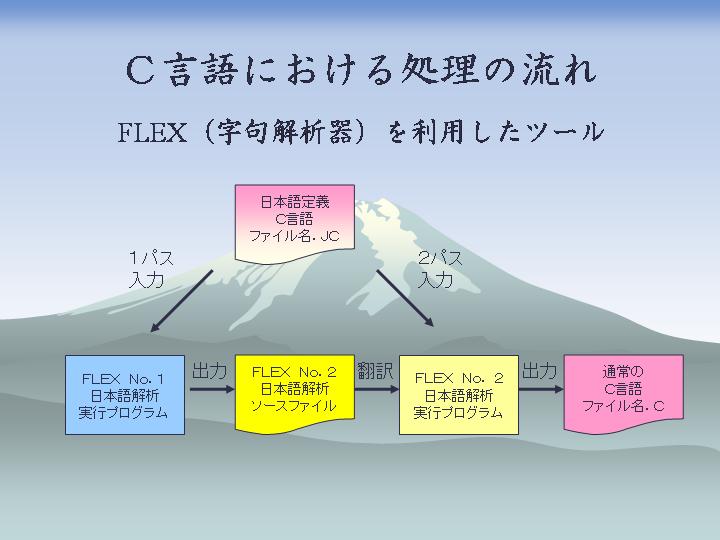
それではここで内容について、論文から抜粋したものを掲載します。
日本の文字の歴史について簡単に述べますと、漢字が一番古く、次が片仮名、一番新しいのが平仮名です[1]。日本人の母国語である日本語は「やまとことば」と呼ばれ先祖伝来受け継がれてきました。この日本語をより多く使用してプログラム言語を記述することについて、一つの試行実験を行いましたのでそれについて述べます。
日本には古くから言霊(ことだま)という言葉に宿る霊妙な力があると信じられてきました。例えば万葉集には「言霊のさきはふ国」(山上憶良)や「言霊のたすくる国」(柿本人麻呂)という歌が出てきます。このように日本語には世界のほかの言語にはない特徴を持ち、長い歴史と文化の流れの中で発展してきた言語だといえます。
日本語は欧米で使用されている言語、特に英語と比べて非常に文字集合が多いことが挙げられます。これはアルファベット26文字で構成されている英語に対して、例えばJIS基本漢字(JIS X 0208)の場合、 漢字だけを考えても六千種類以上のコードが割り当てられています。このように長い歴史的な文字文化の蓄積もあり、日本語には優れた意味や感情を表現する文字力が備わっているのではないかと考えられます。
かつて自然言語においては、万国共通で使用できる言語としてエスペラント語というものが提唱されました[2]。プログラム言語の世界で、このような万国共通の自然言語を用いて記述していこうという大きな潮流は起こっていないとみられますが、プログラム言語における英語圏の果たす役割は大きいのではないかと考えられます。
これについて,例えばスイスで開発されたPascalやフランスで最初に開発されたprologなどがあるように、欧米を中心にプログラム言語の核となる思想的な研究が多くなされています。しかし日本でこれらのプログラム言語が利用される場合、その多くは英語が主な記述語として使われているものとみられます。つまりスイスやフランスで開発されたものであっても日本では外来の言語処理システムが国内で利用される場合には、ほとんど英語によりプログラム言語を記述するようになっているのが現状ではないかと考えられます。
4-1.日本語の有用性
前記のように日本語の歴史的な背景の中で、欧米社会が発祥であり、英語で記述しなければならないプログラム言語を多くの日本人が利用していることについては、すでに日常化しているものとみられます。
しかしながらこのプログラム言語は、日本人が日常生活で用いる言葉とは異なり、専門分野に特化された用語が新語、造語を含めて数多く使われています。また、コンピューターが現代社会の中で便利な道具としてのゆるぎない地位を確立していることは、多くの人々が実感していることだと考えられます。ゆえにプログラム言語は人間のさまざまな活動を支えるための中核的な道具であるとも言えます。
一方、これは人間が日常無意識に使用している自然言語に比べると、はるかに限定的な理解しかできません。そこで、文化や習慣の異なる国々において、日々驚異的なスピードで研究、開発、発展され続けているプログラム言語を分かりやすい日本語で多く記述することができれば、人間の理解を助け複雑な論理を分かりやすくする可能性があるのではないかと考えています。
4-2.計算機の構成とプログラム言語
普通、人が読んで分かりやすいプログラムとは、それを作った人が何度も何度も見直しや書き直しを行います。また、意図どおりに働いてくれるかということだけではなく、プログラム中のさまざまな名前(特定のプログラム言語では識別子という言い方もあります)の付け方にも気を配ります。
それは計算機の歴史によれば、順序機械という非常に低いレベルの構成要素を積み上げることから始まり、万能Turing機械[3]に代表される構造に発展したといわれています。また、プログラムはそれを動作させる抽象的な部分に人間の意図を反映するという働きを持っていますので、プログラムを作った人間が処理の流れをより理解しやすくするために、母国語を使用することは極めて重要なことだと考えられます。
また、このことは日本語で文章を書くときと同じように、作家が何度も推敲を重ねて読みやすい文章に仕上げていく過程に相通じるものがあるのではないかともみられます。さらに社会的にも有用なプログラムは、高度な思考に基づいた著作物として認められていることからも、知的作業であることは周知のとおりです。
しかしながら、日常プログラムを書くことを業とする人でさえ、納期に追われて不本意ながら不適切な名前を付けたプログラムを書いた後、一定期間後に再度そのプログラムを眺めてみると、意図が理解できにくいプログラムとしてその保守に苦労した経験のある方も多いのではないでしょうか。これはやはり大部分が英語で書かれていることにより、わずかな語数で記述できる半面、場合によっては直接的な論理の理解を防げている一面もあるのではないかと考えられます。
4-3.FLEXツールについて
ここで具体的なプログラム言語としてC言語[4]の場合を例にあげますと、多くの処理系ではなぜ変数名や関数名に漢字や平仮名が使えないのだろうと疑問に思う人はいるのではないでしょうか。そこでプログラムの中に何とか日本語を多めに利用できないものかと考えた結果、有限オートマトン[3]といわれるアルゴリズムにより構成されたFLEX[3][5][6][7][8]という字句解析器をツールとして利用することで日本語化を試みることにし、これを「日本語カスタマイザー」と名付けることにしました。
中略
(5.~7.部分はカスタマイザーの仕様や実装コード、テスト結果、などについてです)
現在C言語でもさまざまな評価を行っていますが、これ以外にもオブジェクト指向言語と呼ばれるC++言語、Java言語などの適用についての検証も行っています。いずれも良好な結果が得られているのではないかとみています。
C言語はアルゴル(Algol)言語からの派生言語である[10]ということですが、アルゴル言語は文脈自由型言語(context free language)と密接な関係があります[3]。つまりC言語もアルゴル的言語の一種であることから、日本語カスタマイザーは文脈自由型言語について有効な結果が得られているのではないかと考えられます。またC++言語、Java言語なども系統を考慮すると構造化言語であり、アルゴル的言語の一種であることから有用性が確認されているのではないかと推測されます。
一方、同じプログラム言語でもFortran言語については構造化Fortranと呼ばれるRatfor言語[4]があります。これは日本語カスタマイザーがそのまま適用できるのではないかと考えています。しかし通常のFortran言語の流れをくむものなどは一つの行における、 桁の役割に注意する必要があるとみられます。例えば1~5桁目に記載するステートメント番号フィールドの数字を別の識別子に変更するときなどは、変更後にFortran文法における各 桁の規定が守られているかということが日本語カスタマイザーを適用する条件の一つになるのではないかと考えられます。
また、さまざまなプログラム言語における評価にあたり、日本語カスタマイザーもそれぞれの言語に合わせて柔軟な対応が必要になることも十分予想されます。このため一つの言語における評価においても、多くのケースを想定して検証する必要があるのではないかと考えています。
この試作にあたり、実行環境による差はあるかもしれませんが、日本語定義命令語が二千ぐらいまでであれば、このカスタマイザーにより自動的に文字列の置き換えができることを確認しています。さらに、チームで比較的大規模なソフトウェア開発を行う場合を想定してみますと、個々に分割化能な部分(例えばモジュールやクラスライブラリー単位など)に分けるときには、入出力のインターフェースをあらかじめ決めておくことが重要だと考えられます。また、一つの分割可能な部分を複数人で開発、デバッグする場合には日本語定義で使用する日本語文字列の使い方を統一しておく必要があるのではないかとみられます。
本論文の日本語化についての方法はマクロ定義の派生的手法なのか、メタ言語のようなより上位レベルの概念に含まれるのかは有識者でも意見の分かれるところではないかとみていますが、現時点では特定のプログラム言語に依存する必要がないことと、日本語定義命令語をプログラム内に埋め込み可能であるということから、メタ言語という位置付けをしています。
もし機会がありましたら関数型やオブジェクト指向型言語だけではなく、記号処理型言語や論理型言語など、さまざまなプログラム言語について日本語カスタマイザーを適用させる試行実験を行い、その有用性を確かめてみたいと考えています。
また日本語だけにとどまらず、UNICODEを利用した多国語への対応が可能かどうかということも一つの検討課題です。
(注)文中、原論文では「けた」と平仮名表記してありましたが、2010年末に新常用漢字として「桁」が認められていますので、「けた」は「桁」と漢字表記しています。
本論文の著作権は情報処理学会に帰属します。ご利用に当たっては「著作権法」ならびに「情報処理学会倫理綱領」に従うことをお願いいたします。
![]()
![]()
参考文献
[1]岡田茂吉全集 岡田茂吉著 岡田茂吉全集刊行委員会 (1992-2002) 長崎県立図書館蔵書
[2]Language And Culture R.A.Hall & Others edited by JACET Eichosha P.C.L.
[3]オートマトンと言語理論 本多波雄著 コロナ社 (1972)
[4]プログラミング言語C B.W. Kernighan, D.M.Ritchie著 石田晴久訳 共立出版 (1981)
[5]UNIX 石田晴久著 共立出版 (1983)
[6]UNIXプログラム環境 B.W.Kernighan, Rob Pike, 石田晴久監訳 アスキー出版 (1985)
[7]Yacc/Lex 五月女健治著 啓学出版 (1992)
[8]FLEXドキュメント University of California. Vern Paxsonほか多数のAuthor編著
[9]移動体通信の基礎理論における一つの考察 野口謙一 平成18年度電気関係学会九州支部連合大会 (2006)
[10]Bjarne Stroustrup's homepage B.ストラウストラップ博士が公開しているホームページ