
(ubuntu 13.10/14.04LTS/18.04LTS/
20.04LTS/Android版)
今回は超高級言語である数式処理システムREDUCEを日本語で動かしてみたいと思います。REDUCE自体はLISPというプログラム言語で書かれています。(ただしAndoroid版のREDUCEはJava言語で実装されているそうです。)また、LISPという名前はLIST-PROCESSORから付けられたということですから、LIST処理が得意のプログラム言語です。人口知能向け言語とも言われていますが、今でも愛好者の方は大勢いらっしゃるようです。このLISPで書かれた数式処理システムREDUCEの詳しい文法解説はここではしませんが、煩雑な代数計算、微積分計算、行列計算なども人間に代わって自動でやってくれる便利なツールとして有名なものです。
筆者の高校時代には、手のひらに乗る8桁表示電卓で三角関数計算が瞬時にできることに驚いたことを覚えています。また、大学時代には当時のTSS大型計算機でやっとLISPが動き出して「REDUCE」がインストールされ始めたぐらいの頃でした。しかし、現在ではパソコンはおろか、手で簡単に持ち運びできるモバイル端末で、誰でもREDUCEが使えるようになっています。
準備としてはAndroid9タブレットの端末に日本語表示のできるREDUCE for Androidをインストールしておきます。Android9のタブレットでflexが使用できれば良いのですが、そこまでの環境を整備していませんのでubuntuでREDUCE用の日本語カスタマイザーを動かします。このとき、Android9版REDUCEで読み込めるファイル名として「reduce_io.txt」にしておきます。(下のスクリーンショットはREDUCE for Androidの説明画面)
準備ができたところで早速日本語で動かしてみたいと思います。例題としては、java言語編でも取り上げた円周率πを小数点以下三万桁まで求めるというプログラムを日本語で書きました。REDUCEには予約語としてPIという定数が定義されています。デフォルトでは円周率PIは文字「π」としてしか表示されませんので、小数化して小数点以下三万桁を表示させてみます。まずはこれをubuntu20.04(本家公式版)のgeditで日本語プログラムを書き、pi.jredというファイル名を付けます。
#日本語定義 円周率 "pi"
#日本語定義 精度 "precision"
#日本語定義 小数化 "on rounded"
#日本語定義 三万一桁 "30001"
小数化;
精度 三万一桁;
円周率;
三万一桁というのは、小数点以上の「3」を含む小数点以下三万桁表示ということで、表示桁を三万一桁に設定しています。プログラムはご覧のように表示の小数化設定をして、精度を三万一桁にした後、円周率を求めるという非常に簡単なものです。日本語で書かれたREDUCEバッチファイルの名前を仮にファイル1.jredとすると
$./jred ファイル1
というシェルスクリプトによりreduce_io.txtを生成します。jredの内容を次に示します。
#!/bin/bash
./jred_rule < $1.jred > jred_rule2.lex
flex -ojred_rule2.c jred_rule2.lex
gcc -ojred_rule2 jred_rule2.c
./jred_rule2 < $1.jred > reduce_io.txt
exit 0
以下は、πを小数点以下三万桁まで求める日本語REDUCEバッチファイルを日本語カスタマイザーでreduce_io.txtに変換した結果です。
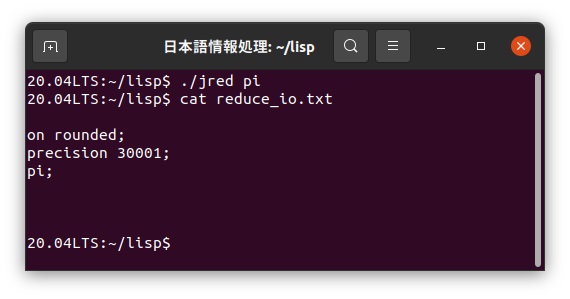
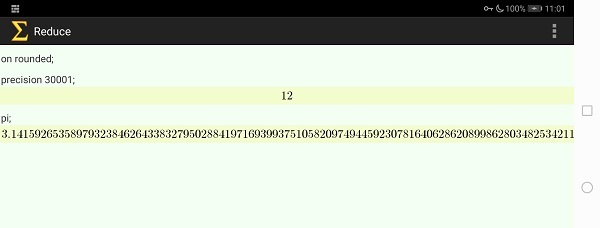
このreduce_io.txtファイルをAndroidタブレットのdownloadフォルダに転送すると、Android版のREDUCEでバッチファイルとして読むことができます。これを実行すると以下のように円周率の最初の部分を表示します。
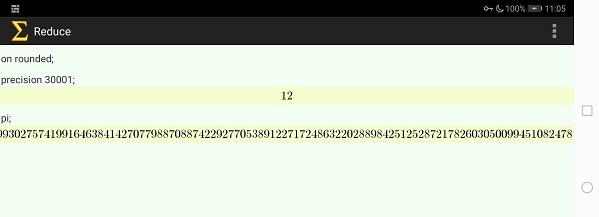
小数点以下三万桁というとかなり長いのですが、表示部分をタッチパネルで横スクロールできるようになっているので、せっせとスクロールして最後の桁部分を表示したのが以下のスクリーンショットです。 Javaの練習問題でやりました円周率小数点以下三万桁の結果と一致していることが分かります。
円周率は無限に続く循環しない数であると数学者は証明しているとのことですが、現在までのところ円周率が収束したという話も聞きませんし、循環しているという話も聞きませんので、やはり無限に続く無理数ということなのかもしれませんが、どこか人の心を惹きつける神秘を感じさせる数列だと思います。
次に円周率と同じように、無限に続く循環しない数といわれている自然対数の底「e」をREDUCEで求めてみたいと思います。これも先の円周率πと同じubuntu20.04のgeditで日本語プログラムを書き、e.jredという名前を付けます。
#日本語定義 自然対数の底 "e"
#日本語定義 精度 "precision"
#日本語定義 小数化 "on rounded"
#日本語定義 三万一桁 "30001"
小数化;
精度 三万一桁;
自然対数の底;
そして日本語カスタマイザーでreduce_io.txtを作成します。
reduce_io.txtをAndroidタブレットのdownloadフォルダに転送した後、Android版REDUCEで読み込んでみます。
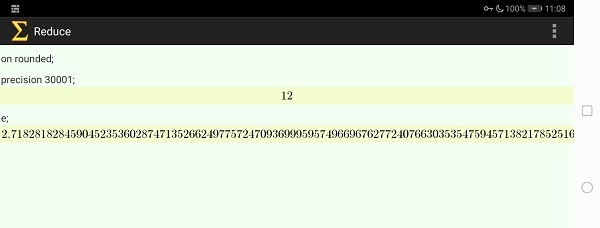
手持ちのクワッドコアAndroidタブレットで十秒程度待つと、自然対数の底の最初の部分が表示されました。三万桁の最後の部分を表示するためには、タッチパネルで横スクロールします。
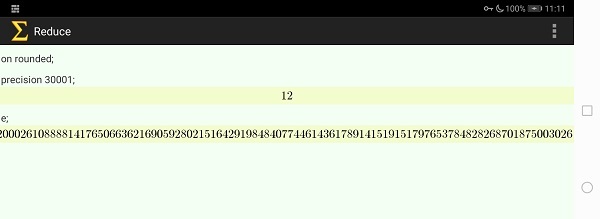
ネットで見つけた自然対数の底の小数点以下三万桁の結果と比べてみましたが、見事に一致していました。 これを覚えるのに「鮒、一箸二箸、一箸二箸、至極惜しい」とか言って覚えた人も多いのではないでしょうか。 微分積分学をやると必ず出てくるのが自然対数の底「e」です。果たしてこの数は、円周率と同じような無限に続く循環しない数なのでしょうか。
次は他の言語編でもおなじみでですが、西暦を指定すると「うるう年」かどうかの判定を行うプログラムをAndroid版のREDUCEで実行してみます。前回までは日本語REDUCEプログラムにはコメントを入れていませんでしたが、 REDUCEには「%」に続く文字列で指定するやり方と「COMMENT~;」または「COMMENT~$」で指定する方法があります。(この「COMMENT」は大文字でも小文字でもどちらでもコメントと判断してくれます) 今回は2023年が「うるう年」かどうかを判定するようにし、ファイル名も「うるう年.jred」にしました。また、プログラム中にコメントも入れてみました。
% うるう年を求めるプログラム
年:=2023;
もし 剰余(年,400)が割り切れる ならば 表示 年,"年はうるう年である"$$
それ以外 もし 剰余(年,100)が割り切れる ならば 表示 年,"年はうるう年でない"$$
それ以外 もし 剰余(年,4)が割り切れる ならば 表示 年,"年はうるう年である"$$
それ以外 表示 年,"年はうるう年でない";
#日本語定義 年 "year"
#日本語定義 剰余 "remainder"
#日本語定義 もし "if"
#日本語定義 それ以外 "else"
#日本語定義 ならば "then"
#日本語定義 が割り切れる "=0"
#日本語定義 表示 "write"
他のパソコン版REDUCEでは
IF 条件式1 THEN 文1
ELSE IF 条件式2 THEN 文2
ELSE 文3;
など複数行に分けて記述できる式でも、問題なく実行してくれるのですが、Android版のREDUCEでは複数行に分けるとエラーが出ます。そこでAndroid版REDUCE用の日本語カスタマイザーで行末に「$$」を指定すると、 「$$改行」を自動的に削除してくれるように改良しました。このAndroid版の問題が解決されるまでは、とりあえずこのように書くことにします。また、PC版REDUCEとは違い、変数名にアンダースコアは使えないようです。
次に日本語カスタマイザーでreduce_io.txtを作成します。
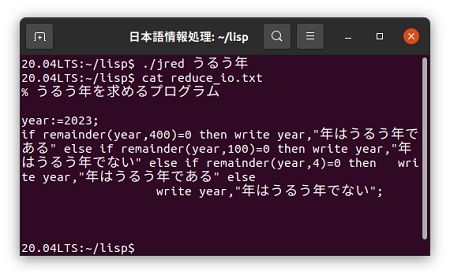
このreduce_io.txtをAndroidタブレットのdownloadフォルダに転送した後、Android版REDUCEで読み込んで実行してみます。

今度はREDUCEのsolveという機能を使って連立一次方程式を解いてみます。例題として農協(JA)のライスセンターにある倉庫を思い浮かべてください。 この倉庫には鍵のかかったコンテナの中に、お米のブランド米として有名な「こしひかり」と「つや姫」が全部で50袋混載されて積み込まれています。こしひかりは1袋に30kg、 つや姫は一袋に20kgの米が入っています。コンテナには鍵がかかっているので、中身を見ることはできませんが、重さを量ったところコンテナだけの 重さを差し引くと1,350kgでした。このときコンテナの中には「こしひかり」と「つや姫」が、それぞれ何袋ずつ入っているかを考えてみます。
解き方としては次のような連立方程式を解けばよいことが分かります。
30kg×こしひかりの数+20kg×つや姫の数=1,350kg
こしひかりの数+つや姫の数=50袋
これをREDUCEで実行するには、solveという機能を使って上記の方程式を書き込んでいきます。Android版のREDUCEはどうやら変数に日本語が使えるようですので、
予約語のsolveだけを日本語カスタマイザーで「解を求める」と文字列変換しました。
#日本語定義 解を求める "solve"
解を求める({30*ひのひかり+20*つや姫=1350,ひのひかり+つや姫=50},{ひのひかり,つや姫});
このファイルを日本語カスタマイザーでreduce_io.txtに変換します。
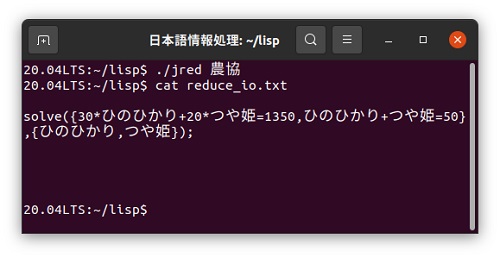
reduce_io.txtをAndroid版REDUCEで実行した結果です。ひのひかりが35袋、つや姫が15袋と答えを出してくれました。

もちろん、reduceはandroidだけではなく、ubuntu上でも動作します。次の例題は大学入試でも出されたことのある、変数が極値に限りなく近づくときの関数ですが、これをubuntu20.04LTS版上のreduceで計算してみます。
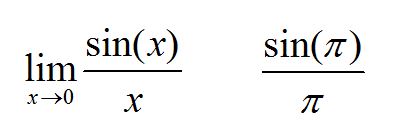
上記左のsin(x)/xという関数は、正弦関数SINの変数xが0のときは、値が0となりますが、分母が0のため関数全体の値は不定になってしまいます。しかし、極限値を考えてやれば発散せずに値は収束することをREDUCEで確認してみます。
右の関数は分母が定数のπで、分子がsin(π)の計算ですが、これは特に極限値を考えなくてもよいのですが合わせてREDUCEで計算してみます。
ubuntu20.04のgeditを使って、日本語reduceプログラム「極限値.jred」を以下のように書いてみました。sin(x)/xで変数が極限値0に限りなく近づくときの関数全体の値は、以下のように極限値を求める(式,変数,極値)という形式で記述します。同じように変数が定数の円周率の場合にも確認してみます。
#日本語定義 変数
#日本語定義 正弦関数 "sin"
#日本語定義 極限値を求める "limit"
#日本語定義 円周率 "pi"
#日本語定義 終了 ";end"
極限値を求める(正弦関数(変数)/変数,変数,0);
正弦関数(円周率)/円周率;
終了;
日本語カスタマイザーで「極限値.jred」を読み込ませて、この結果を「reduce_io.txt」というファイルに書き込みます。
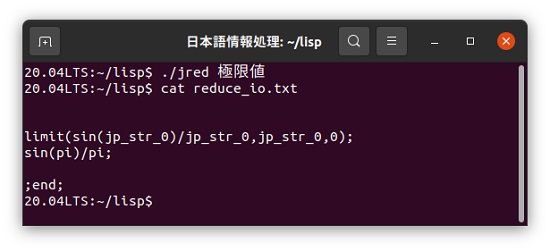
ここでubuntu20.04でREDUCE csl版を起動させて、この「reduce_io.txt」というREDUCEファイルを読み込むと、自動的に計算結果を表示します。
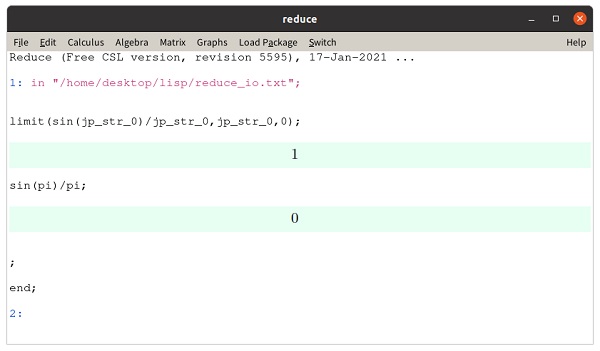
この結果からsin(x)/xで変数が極限値0に限りなく近づくときの関数全体の値は1、変数が定数の円周率の場合の関数全体は0となることが分かります。
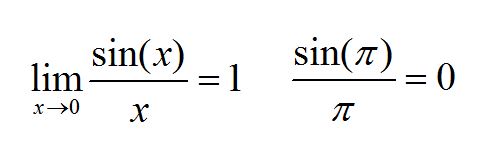
最後に、この関数y=sin(x)/xをREDUCEのGNUPLOT機能で図示します。このときx=0ではyは定義されませんが、xが0に非常に近い極限の近傍で、yは1という値に収束します。 (×マークはy=0のとき)
ここでubuntu上で動作するlisp処理系「clisp」についても日本語化してみたいと思います。使用するclispのバージョンを以下に示します。
lispのコメントは「;~行末」がコメントとして認識されますので、lisp用日本語カスタマイザーをそのように作成しました。プログラム例として、集合計算をやってみます。geditで以下のように 日本語プログラムを書いてみました。代入操作をする「setq」は全角記号の「:=」としました。また、改行付き表示と改行なし表示を分けて定義しています。集合演算子は数学記号を使ってみました。 clispでは二つの集合が部分集合の関係にあるかどうかを判定する関数「subsetp」が用意されているので便利です。
; 集合計算のプログラム
(:= 鳥類 '(鶴 タカ ハト 鴬 すずめ))
(:= 猛禽類 '(タカ 鷲 トンビ))
(:= 魚貝類 '(鯛 サバ 鰯 カキ はまぐり))
(:= 貝類 '(カキ はまぐり))
(表示一 鳥類) (表示一 "と" ) (表示一 魚貝類)
(表示一 "の和集合は" )
(表示二 (∪ 鳥類 魚貝類)) (改行) (改行)
(表示一 鳥類) (表示一 "と" ) (表示一 猛禽類)
(表示一 "の積集合は" )
(表示二 (∩ 鳥類 猛禽類)) (改行) (改行)
(表示一 貝類) (表示一 "は" ) (表示一 魚貝類)
(表示一 "に" )
(もし (⊆ 貝類 魚貝類)
(表示一 "含まれる") (表示一 "含まれない"))
#日本語定義 ∪ "union"
#日本語定義 ∩ "intersection"
#日本語定義 ⊆ "subsetp"
#日本語定義 := "setq"
#日本語定義 もし "if"
#日本語定義 表示一 "princ"
#日本語定義 表示二 "print"
#日本語定義 改行 "princ #\\newline"
#日本語定義 鳥類
#日本語定義 猛禽類
#日本語定義 魚貝類
#日本語定義 貝類
clisp用日本語カスタマイザーjlispの内容は次のようになります。
#!/bin/bash
./jlisp_rule < $1.jlisp > jlisp_rule2.lex
flex -ojlisp_rule2.c jlisp_rule2.lex
gcc -ojlisp_rule2 jlisp_rule2.c
./jlisp_rule2 < $1.jlisp > $1.lisp
exit 0
jlispで「集合計算.jlisp」から「集合計算.lisp」を作成します。
集合計算.lispは以下のようになります。
; 集合計算のプログラム
(setq jp_str_0 '(鶴 タカ ハト 鴬 すずめ))
(setq jp_str_1 '(タカ 鷲 トンビ))
(setq jp_str_2 '(鯛 サバ 鰯 カキ はまぐり))
(setq jp_str_3 '(カキ はまぐり))
(princ jp_str_0) (princ "と" ) (princ jp_str_2)
(princ "の和集合は" )
(print (union jp_str_0 jp_str_2)) (princ #\newline) (princ #\newline)
(princ jp_str_0) (princ "と" ) (princ jp_str_1)
(princ "の積集合は" )
(print (intersection jp_str_0 jp_str_1)) (princ #\newline) (princ #\newline)
(princ jp_str_3) (princ "は" ) (princ jp_str_2)
(princ "に" )
(if (subsetp jp_str_3 jp_str_2)
(princ "含まれる") (princ "含まれない"))
clispの実行は「clisp ファイル名」ですから、これを実行して集合演算が正しく行われていることを確かめました。

オブジェクト指向スクリプト言語として有名な「Ruby」で、日本語カスタマイザーを使ってみたいと思います。Rubyは日本人の松本行弘さんという方が開発されたということです。 ubuntu20.04上で動作するRubyのバージョンを以下に示します。
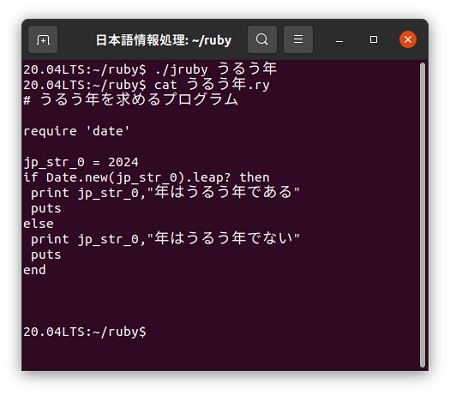
度々ですが西暦を指定して、うるう年かどうかを判定するプログラムをRuby用日本語カスタマイザーで書いてみました。Rubyのコメントは「#~行末」と「=begin~=end」などですが、一応この二種類について対応するようにしています。 RubyはJavaと同じように標準で使い勝手の良いクラスライブラリーが提供されています。今回もこの中の「date」という日付の取り扱いに関するクラスライブラリーを利用して、「new」で物理的なメモリー上にオブジェクトとして割り付けるようにしています。 そして、うるう年は「leap」というメソッドで求めるようにしていて、うるう年かどうかを判定する西暦は新元号の始まる2024年に設定しています。
# うるう年を求めるプログラム
日付の仲間を呼ぶ
年 = 2024
もし 「西暦」(年)はうるう年なのか? ならば
表示 年,"年はうるう年である"
改行
それ以外
表示 年,"年はうるう年でない"
改行
ここまで
#日本語定義 年
#日本語定義 日付の仲間を呼ぶ "require 'date'"
#日本語定義 表示 "print"
#日本語定義 「西暦」 "Date.new"
#日本語定義 はうるう年 ".leap"
#日本語定義 なのか? "?"
#日本語定義 もし "if"
#日本語定義 ならば "then"
#日本語定義 それ以外 "else"
#日本語定義 ここまで "end"
#日本語定義 改行 "puts"
ここでruby用日本語カスタマイザー「jruby」の内容は、次のようになります。
#!/bin/bash
./jruby_rule < $1.jry > jruby_rule2.lex
flex -ojruby_rule2.c jruby_rule2.lex
gcc -ojruby_rule2 jruby_rule2.c
./jruby_rule2 < $1.jry > $1.ry
exit 0
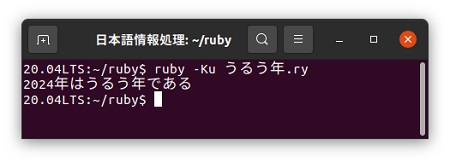
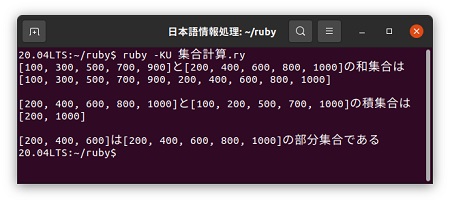
「うるう年.jry」はjrubyを使い、「うるう年.ry」を作成します。 実行は「ruby -Ku ファイル名」で実行しますが、オプションの「-Ku」は、Ruby処理システムにUTF-8コードが漢字として使われることを知らせています。
これを実行すると2024はうるう年であると判定されました。
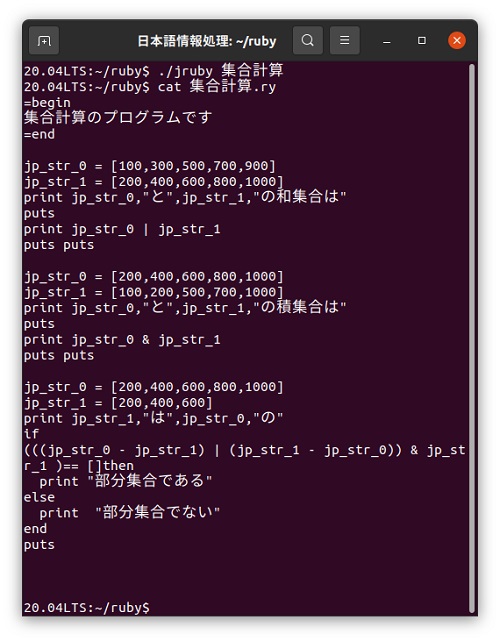
次にWindows版のC++言語でもやりました集合計算をRubyでやってみたいと思います。 C++では「クラス」で集合演算を行う前に、リストにデータを入力する操作がちょっと面倒だったのですが、Rubyではリスト間で直接集合演算ができるので便利です。 直接的に分かりやすいように、集合演算に「∪∩―」で和集合、積集合、差集合を使っています。また、部分集合かどうかの判定は、これらの演算を組み合わせて判定しています。Rubyではコメントに「#」が使われているため、FLEXで日本語カスタマイザーの作成処理をするときに「#日本語定義」の先頭「#」と衝突が起こってしまいます。そこで全角「#」を使って、Ruby用の日本語プログラムでは「#日本語定義」としてコメントの半角「#」と区別をしています。
=begin
集合計算のプログラムです
=end
集合1 = [100,300,500,700,900]
集合2 = [200,400,600,800,1000]
表示1 集合1,"と",集合2,"の和集合は"
改行
表示1 集合1 ∪ 集合2
改行 改行
集合1 = [200,400,600,800,1000]
集合2 = [100,200,500,700,1000]
表示1 集合1,"と",集合2,"の積集合は"
改行
表示1 集合1 ∩ 集合2
改行 改行
集合1 = [200,400,600,800,1000]
集合2 = [200,400,600]
表示1 集合2,"は",集合1,"の"
もし
(((集合1 ー 集合2) ∪ (集合2 ー 集合1)) ∩ 集合2 )が空集合ならば
表示1 "部分集合である"
それ以外
表示1 "部分集合でない"
ここまで
改行
#日本語定義 もし "if"
#日本語定義 ならば "then"
#日本語定義 それ以外 "else"
#日本語定義 ここまで "end"
#日本語定義 集合1
#日本語定義 集合2
#日本語定義 表示1 "print"
#日本語定義 改行 "puts"
#日本語定義 ∪ "|"
#日本語定義 ∩ "&"
#日本語定義 ー "-"
#日本語定義 が空集合 "== []"
日本語カスタマイザーで「集合計算.jry」から「集合計算.ry」を作成します。
これを実行して集合演算が正しく行われていることを確かめました。
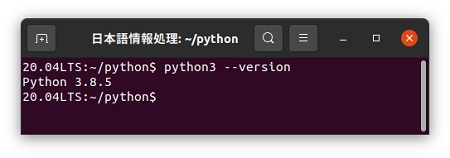
21世紀に入って急速にユーザーが広がってきたオブジェクト指向言語としては「Python」があります。Pythonはオランダ人のグイド・ヴァンロッサムというプログラマーが発案者として知られています。 Pythonは「大蛇」の名前ですが、その名前の由来のように、これまでのさまざまなプログラム言語の要素を兼ね備えた(どんどん丸呑みしている)ような、多彩な特徴があると感じています。 今回使用したPythonのバージョンを以下に示します。
ここでは現在の情報処理技術にはかかせないデータ圧縮についてPythonでやってみたいと思います。まず以下のような日本語の文章を「元データ.txt」 というファイル名で作成しておきます。
坊主が屏風にじょうずに坊主の絵を書いた。
赤巻紙、青巻紙、黄巻紙。
庭には二羽裏庭には二羽鶏がいる。
隣の客はよく柿食う客だ。
東京特許許可局。
次にPython用の日本語カスタマイザーでこの「元データ.txt」を読み込んで圧縮するプログラムを作成します。Pythonで情報の圧縮操作をするときには、便利な「zlib」というパッケージが利用できます。 Zlibにはdeflateと呼ばれるアルゴリズムが採用されているとのことです。これは情報元系列の重複する部分を(一致長、一致位置)の対にして符号化し、そのうち情報と一致長をハフマン符号で符号化し、 一致位置を別のハフマン符号で符号化するという方式らしいです。
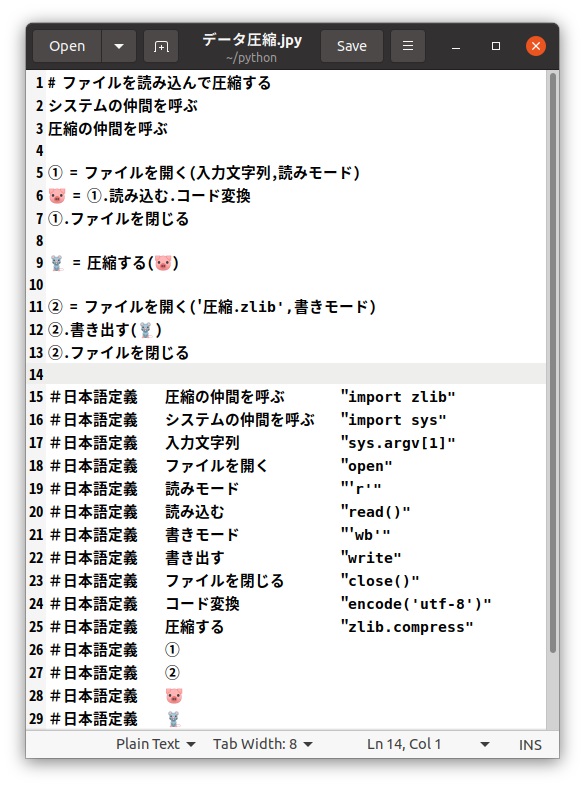
プログラムの中では、ファイルを開くときにファイル識別子というものを定義しますが、これはどんな文字列でもよいので、「①」という短い記号を付けてみました。 また、テキストファイルから文字列を読み込んだときの変数にも絵文字を用いてみました。情報圧縮は非常に簡単で、「zlib.compress(バイナリデータ列)」を使うだけです。このとき注意しないといけないのは、文字列ではなくバイナリ(二進数)として取り扱う必要があるので、あらかじめ「encode('utf-8')」で文字列からバイナリに変換しておきます。 圧縮されたデータは、絵文字として取り扱い、「圧縮.zlib」というファイルに書き出しています。また、ファイルに書き出すときには「'wb'」というバイナリ書き出しモードにしておく必要があります。豚の顔マークやねずみマークの絵文字は、UTF-8の4byteコードです。python用の日本語カスタマイザーではこの絵文字も処理できるようにしています。
python用日本語カスタマイザー「jpython」の内容は次のようになります。
#!/bin/bash
./jpython_rule < $1.jpy > jpython_rule2.lex
flex -ojpython_rule2.c jpython_rule2.lex
gcc -ojpython_rule2 jpython_rule2.c
./jpython_rule2 < $1.jpy > $1.py
exit 0
jpythonを使って「データ圧縮.jpy」をPython処理系で実行できる「データ圧縮.py」に変換します。 PythonはRuby同様コメントに半角の「#」が使われているため、Python用の日本語プログラムでは全角「#」を使って「#日本語定義」として半角「#」と区別をしています。
日本語カスタマイザー「jpython」で「データ圧縮.py」が作成されていることが分かります。
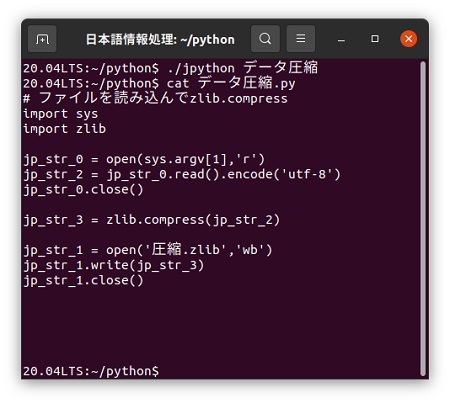
プログラムの実行は、「python3 ファイル名」です。「データ圧縮.py」を実行した結果、「圧縮.zlib」という大きさ160バイトのファイルができていました。
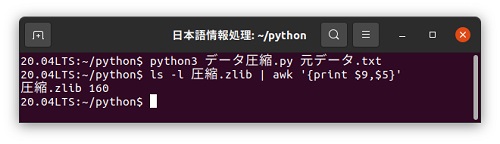
次に「圧縮.zlib」というファイルを復元して表示するプログラムを日本語カスタマイザーで書いてみます。圧縮ファイルの復元には「zlib.decompress」を使うだけです。 復元されたバイナリデータは白い顔マークとして取り扱い、表示するときには「decode('utf-8')」を用いて文字列としてあります。 ここで注意する点としては、ファイルを読み込むときの「読みモード」は「'rb'」というバイナリモードで読み込むようにしています。先の圧縮プログラムでは テキストモード「'r'」で読み込むときにも、同じ「読みモード」という語句を使っていましたが、別プログラムのために不具合はありませんでした。 もし、同じプログラムの中でバイナリファイルとテキストファイルの読み込みを両方行う場合には、語句を別にして使わないといけません。
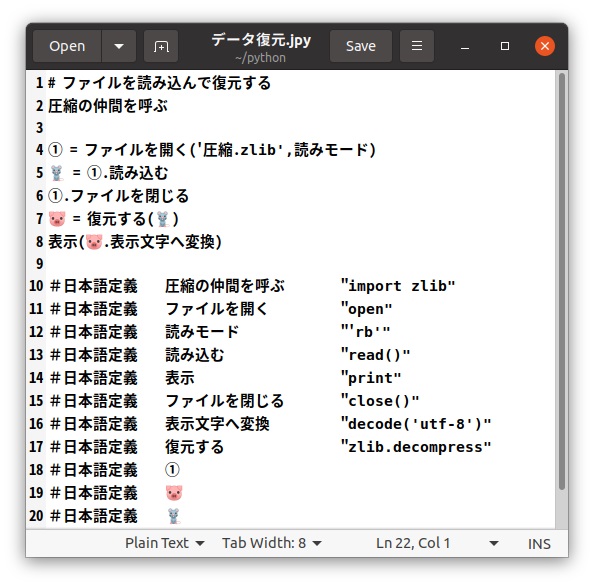
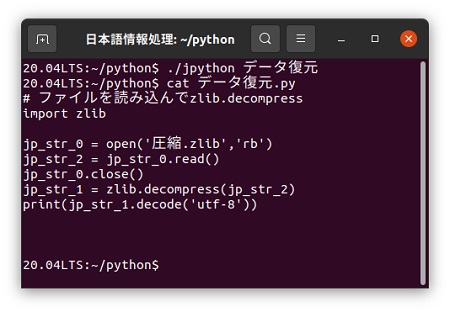
日本語カスタマイザーを使って「データ復元.jpy」をPython処理系で実行できる「データ復元.py」に変換します。 「jpython」で「データ復元.py」が作成されています。
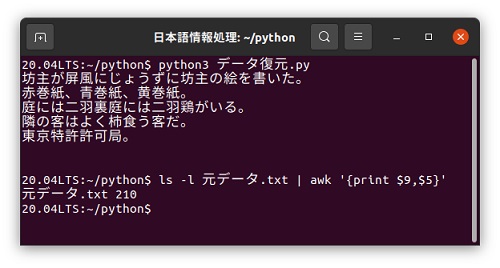
「データ復元.jpy」を実行すると、「圧縮.zlib」を読み込んでこれを復元して表示しましたが、データが復元されていることが分かります。 元データの大きさを調べてみると210バイト、圧縮すると160バイトでしたので、この例では23%程度圧縮されていました。
HTMLとは、Hyper-Text-Markup-languageの略語です。これはインターネットの普及発展に伴い、文字、画像、音声などをハイパーリンクを使って世界中で共用することができるように考えられた言語です。 いわゆるタグ付き言語という仲間に入るのかもしれませんが、この言語を使用することで、インターネット上のホームページを記述することができます。
ここではHTML5という規格にある縦書きページを日本語カスタマイザーを使って記述してみます。ただし、どんなブラウザーでも対応できるような記述方法ではなくて、Ubuntuをインストールするとデフォルトで使用できるfirefoxブラウザーで縦書きするためのものであることをお断りしておきます。 従って、メジャーブラウザーの一つともいわれるIEなどで縦書きをするためには、別途それに合う記述の工夫が必要となります。
まず以下のような日本語HTML言語で書いたプログラムを「縦書きテスト.jhtm」 というファイル名で作成しておきます。 現在はHTML+CSS(スタイルファイル)の組み合わせが一般的ですっきりと書けますが、今回はテスト用にHTMLだけで書いてみました。
・文書の宣言
・接頭文
・文字コード定義
・表題「縦書きのテスト」(表題)
・閉(接頭文)
・本文
・縦書『
・見出し「発心集 序」(見出し)
・著者「鴨 長明 撰」(著者)↩
・段落「御仏の教えにある「心の師とはなっても、心を師とするなかれ」とは、実に名言である。人の生涯に思い描くさまざまなことは、悪に属さないものはない。もし、身を整え、衣を清く染めて、世俗の✐「[塵]《ちり》」(✐)に汚されなかった人があったとしても、わが家の犬はなれ親しむけれど、よその鹿は近づかない。ましてや、因果の道理をも分からず富と名声を追い求める過ちに身を置く者は、なおさらのことである。日々を五欲(色・声・香・味・触)の✐「[虜]《とりこ》」(✐)となって暮らし、ついには奈落の底に沈むのであろう。心ある人ならば、きっとこのことを恐れるはずである。」(段落)
・段落「こういうわけであるから、一つ一つの事柄に当って、自分の心がはかなく、愚かなものであることを省みて、仏の教えに従い、自らの心に気を許さなければ、生まれ死に行く✐「[輪]《りん》[廻]《ね》」(✐)から解脱し、速やかに極楽浄土に生まれることは、牧人がどんな気の荒い馬でもうまくならして、遠くへ連れ行くようなものである。」(段落)
・段落「ただ、人の心には、それぞれ強い弱い、浅い深いというものがある。かつ自分の心を客観視してみると、善に背を向けるでもなく、悪から離れようとするのでもない。それは、風に吹かれて草が✐「[靡]《なび》」(✐)くような有様である。また浪の上に映る月影が静まり難いことに似ている。いったい、こんなに愚かな心をどのように教え導こうとするのであろうか。仏は民衆の心が種々様々であることをご覧になり、因縁を通じ、✐「[喩]《たと》」(✐)えを用いて、それぞれに合うように教導され給うのである。(後略)」(段落)
』(縦書)
・閉(本文)
・閉(文書全体)
この日本語プログラムに対応する定義部分です。
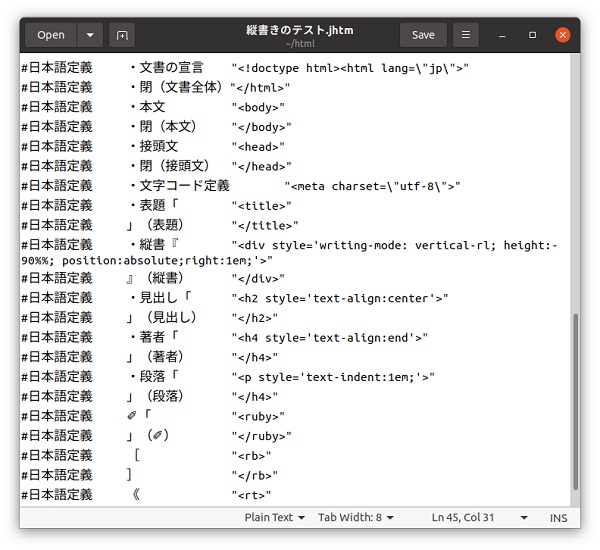
本サイトに掲載しているプログラムはすべてそうですが、こういうように書かないといけないということは一切なく、こういう風にも書くことができますという一例を示しているだけです。 筆者個人的な趣向によって日本語定義を決めていることから、ご批判は多々あると思いますが、これはそういうものだと考えてください。HTML5仕様になって文書型定義(DTD)が簡素化されているようです。 ふり仮名については、それにピタリと当てはまるような記号が見つからなかったので、とりあえず鉛筆マークを使っています。
ここでhtml用日本語カスタマイザー「jhtml」の内容を次に示します。
#!/bin/bash
./jhtml_rule < $1.jhtm > jhtml_rule2.lex
flex -ojhtml_rule2.c jhtml_rule2.lex
gcc -ojhtml_rule2 jhtml_rule2.c
./jhtml_rule2 < $1.jhtm > $1.htm
exit 0
このjhtmlを使って「縦書きテスト.jhtm」をfirefoxで読み込みできる「縦書きテスト.htm」に変換します。
変換された「縦書きテスト.htm」の内容を見てみます。
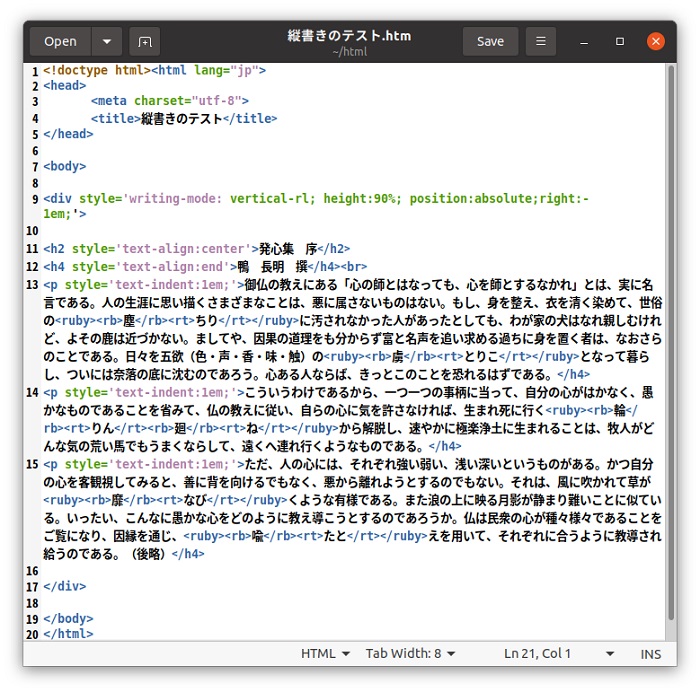
この「縦書きテスト.htm」をfirefox(88.0.1)で読み込んでみます。
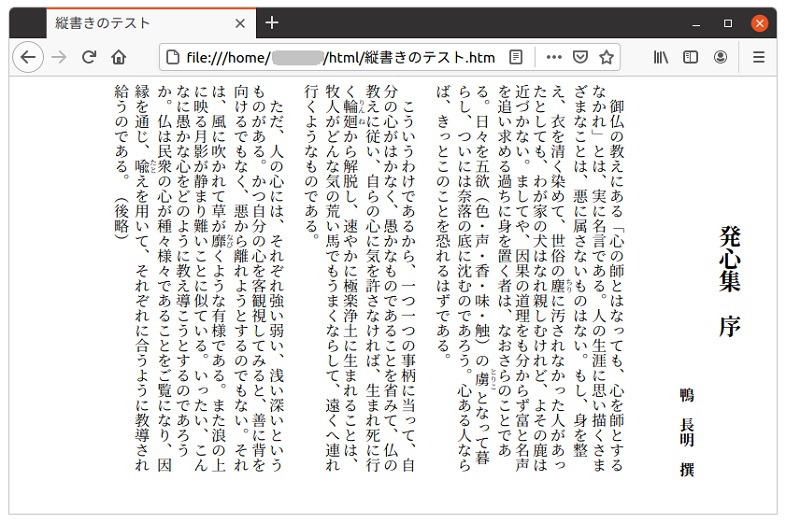
うまく縦書きで表示されています。


参考資料
REDUCE マニュアル
REDUCEで数学を 大河内茂美著 森北出版 1991
発心集 梁瀬一雄注釈 角川文庫 1975