
(windows 10版)
C言語は米合衆国のベル研究所でUNIXオペレーティングシステムのプログラムを書くために誕生した言語として知られています。その後、全世界にUNIXが広がると共にC言語の利用者も多くなり、今日ではFORTRANやCOBOLのようによく利用されているプログラミング言語といえるのではないでしょうか。
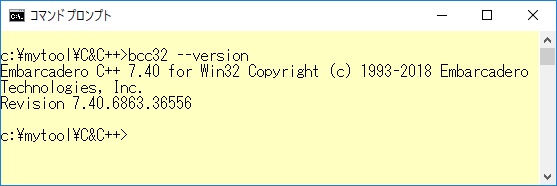
また、C言語は記述の簡潔さにより、多くのプログラマーから支持されていますが、それだけではなくUNIX上のさまざまなツール群がこのC言語の流儀に習って設計されているものが多いため、C言語を直接使わない人でも一度C言語の文法を学習しておくことは大変有用なことではないでしょうか。 Windows10版ではWindows10のコマンドプロンプトを起動させて、プログラムの作成、機械翻訳(コンパイル)、実行を行います。また、C言語の処理系にはEmbarcadero Technologies社のC言語コンパイラーをインストールして使用しました。
日本語で書かれたC言語ファイルの名前を仮にファイル1.jcとすると
>jcc10 ファイル1
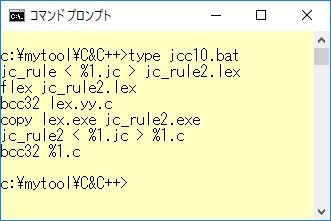
というバッチコマンドによりファイル1.cを生成し、さらに翻訳(コンパイル)、結合(リンク)して、実行可能形式ファイルであるファイル1.exeを生成します。 このとき、jc_ruleがC言語用の日本語カスタマイザー1パス目の実行で、jc_rule2は2パス目の実行を行っています。
ここで、コメントである/* ~ */で囲まれた部分や文字列を表す二重引用符で囲まれた部分に対しては、上記の日本語変換は適用されないようにすることは言うまでもありません。
このバージョンのbcc32をインストールした直後には、ある特定のフォルダ/ディレクトリが見つからないというような警告メッセージが出ましたが、そのメッセージで表示されたフォルダを管理者権限で作成すると、警告は出なくなりました。これは将来的に改善されるかもしれません。

実際のC言語プログラムでの応用例
以下に応用例について説明します。これは硝酸銀の水溶液に電流(電源や電池のマイナス側からプラス側へ移動する、実際のエネルギーとしての電子の流れという意味)を流して、電気分解したときに析出する銀の質量を求めるためのものです。
/* 硝酸銀に1~10アンペアの電流を1時間流して電気分解したとき、陰極に出てくる銀の質量を求める */
#include <stdio.h>
#日本語定義 整数型 "int"
#日本語定義 実数型 "float"
#日本語定義 型なし "void"
#日本語定義 印字 "printf"
#日本語定義 はじまり "main"
#日本語定義 繰り返し "while"
#日本語定義 電流を流したときの電気量
#日本語定義 電流値
#日本語定義 1時間の秒数
#日本語定義 電子がもつ基準の電気量
#日本語定義 銀の原子量
#日本語定義 出てくる銀の質量
#日本語定義 上限
#日本語定義 下限
#日本語定義 きざみ幅
型なし はじまり(型なし)
{
整数型 電流値,上限,下限,きざみ幅;
実数型 1時間の秒数 = 3600.0,
電子がもつ基準の電気量 = 96500.0,
電流を流したときの電気量,
銀の原子量 = 107.9,
出てくる銀の質量;
上限 = 10;
下限 = 1;
きざみ幅 = 1;
電流値 = 下限;
繰り返し ( 電流値 <= 上限 ) {
電流を流したときの電気量 = (実数型)電流値 *1時間の秒数 / 電子がもつ基準の電気量;
出てくる銀の質量 = 銀の原子量 * 電流を流したときの電気量;
印字( "電流値が%dアンペアのとき、出てくる銀の質量は%6.3fgです。\n", 電流値, 出てくる銀の質量 );
電流値 = 電流値 + きざみ幅;
}
}
例1-1
これは次のようなC言語のコードに展開されます。(以降リスト中の余分な空白行は適当に削除して掲載しております)
/* 硝酸銀に1~10アンペアの電流を1時間流して電気分解したとき、陰極に出てくる銀の質量を求める */
#include <stdio.h>
void main(void)
{
int
jp_str_1,jp_str_6,jp_str_7,jp_str_8;
float jp_str_2 = 3600.0,
jp_str_3 = 96500.0,
jp_str_0,
jp_str_4 = 107.9,
jp_str_5;
jp_str_6 = 10;
jp_str_7 = 1;
jp_str_8 = 1;
jp_str_1 = jp_str_7;
while ( jp_str_1 <= jp_str_6 ) {
jp_str_0 = (float)jp_str_1 *jp_str_2 / jp_str_3;
jp_str_5 = jp_str_4 * jp_str_0;
printf( "電流値が%dアンペアのとき、出てくる銀の質量は%6.3fgです。\n", jp_str_1, jp_str_5 );
jp_str_1 = jp_str_1 + jp_str_8;
}
}
例1-1を展開したもの
やはり日本語を多めに書いたプログラムはとても読みやすいと思いますし、頭にスッと入ってくる感じがしますので、後で読んでも手直しなどがとても楽だと思います。余分なコメントなど必要ないぐらいです。
ここで注意しなければならないことは、jp_str_***(***は数字)のような自動的に割り当てる適当な英数文字と#includeで定義されたファイル内の英数文字が衝突しないようにすることです。(これは各処理系にもよると考えられますが、GREPというツールで調べたところ、今回メーカーが提供しているインクルードファイルの中には、幸い衝突するような文字列はありませんでした)
また、FLEXは2バイト目が16進数で5CであるS-JIS日本語コード(例えば「構」、「表」、「申」などの漢字)は文字列としては認識できないようですので、そのまま2バイトコードとして認識させるように例外的な工夫が必要です。
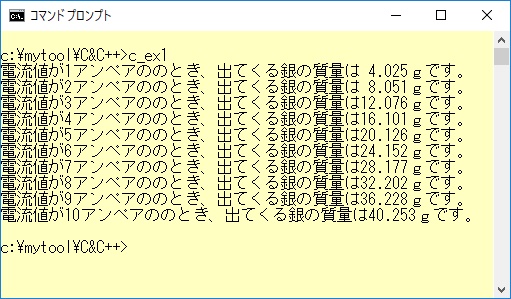
例1の展開されたC言語プログラムをコンパイルして実行させた結果は以下のとおりです。
次に例1の計算式の部分を関数化したものを例1-2とします。
/* 硝酸銀に1~10アンペアの電流を1時間流して電気分解したとき、陰極に出てくる銀の質量を求める */
#include <stdio.h>
#日本語定義 整数型 "int"
#日本語定義 実数型 "float"
#日本語定義 型なし "void"
#日本語定義 印字 "printf"
#日本語定義 はじまり "main"
#日本語定義 繰り返し "while"
#日本語定義 戻る "return"
#日本語定義 電流を流したときの電気量
#日本語定義 電流値
#日本語定義 1時間の秒数
#日本語定義 電子がもつ基準の電気量
#日本語定義 銀の原子量
#日本語定義 電気量を求める
#日本語定義 上限
#日本語定義 下限
#日本語定義 きざみ幅
型なし はじまり(型なし)
{
整数型 電流値,上限,下限,きざみ幅;
実数型 電気量を求める( 整数型 );
上限 = 10;
下限 = 1;
きざみ幅 = 1;
電流値 = 下限;
繰り返し ( 電流値 <= 上限 ) {
印字( "電流値が%dアンペアののとき、出てくる銀の質量は%6.3fgです。\n", 電流値, 電気量を求める(電流値) );
電流値 = 電流値 + きざみ幅;
}
}
実数型 電気量を求める( 電流値 )
整数型 電流値;
{
実数型 1時間の秒数 = 3600.0,
電子がもつ基準の電気量 = 96500.0,
電流を流したときの電気量,
銀の原子量 = 107.9;
電流を流したときの電気量 = (実数型)電流値 *1時間の秒数 /
電子がもつ基準の電気量;
戻る( 銀の原子量 * 電流を流したときの電気量 );
}
例1-2
上記のプログラムは、次のようなC言語のコードに展開されます。
/* 硝酸銀に1~10アンペアの電流を1時間流して電気分解したとき、陰極に出てくる銀の質量を求める */
#include <stdio.h>
void main(void)
{
int jp_str_1,jp_str_6,jp_str_7,jp_str_8;
float jp_str_5( int );
jp_str_6 = 10;
jp_str_7 = 1;
jp_str_8 = 1;
jp_str_1 = jp_str_7;
while ( jp_str_1 <= jp_str_6 ) {
printf( "電流値が%dアンペアののとき、出てくる銀の質量は%6.3fgです。\n", jp_str_1, jp_str_5(jp_str_1) );
jp_str_1 = jp_str_1 + jp_str_8;
}
}
float jp_str_5( jp_str_1 )
int jp_str_1;
{
float jp_str_2 = 3600.0,
jp_str_3 = 96500.0,
jp_str_0,
jp_str_4 = 107.9;
jp_str_0 = (float)jp_str_1 *jp_str_2 /
jp_str_3;
return( jp_str_4 * jp_str_0 );
}
例1-2を展開したもの
ここで整数型の電流値という変数が、jp_str_1としてmain()で使われており、また、別の関数のパラメータとしても使われています。C言語をよく知っている方でしたら、両者は自動変数として全く別物として取り扱いされることが分かると思いますので、プログラムは問題なく動くわけです。
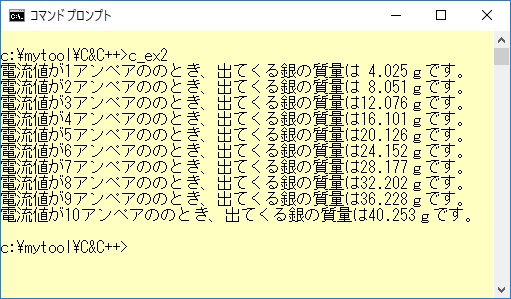
また、例1-2の展開されたC言語プログラムを実行させた結果は例1-1と全く同じものです。
追記 電流と電子の流れについて
よく物理や化学の教科書では、簡単に導体中の電流の向きは、電子の動く向きと反対ですというような解説があります。
上記例題1─1、例題1─2では、この「電流」について、電子の流れを意味するというように使っていますが、詳細については、このサイト内にある「2006年(平成18年)9月、電気関係学会九州支部連合会」を参照してください。
従来よく使われている導体中をプラス側からマイナス側へ動く「電流」という言葉は、「仮想電流」と言い換えた方が分かりやすいと思いますし、エネルギーを伝えるマイナス側からプラス側への電子の流れは、「電子流」という言葉を使った方が本当は良いと思います。
また、例題1─1、例題1─2では、1時間(3,600秒)あたりの硝酸銀の電気分解を行ったときの銀の析出量を求めるプログラムを取り上げていますが、この実験は物理学において以前は重要だったそうです。
物理定数でもある仮想電流1アンペアの定義を行なう方法として、二つのやり方があるそうです。
一つは、現在主流の方法だそうで、(真空中)1mの距離をへだてた2本のまっすぐな平行導体を流れる、相等しい仮想電流間に働く力が、1mあたり2×10-7ニュートンであるときの仮想電流で、定義するという方法です。(しかし、これではニュートン毎平方アンペアという単位を持つ、真空中の透磁率があらかじめ決定されたことになり、マックスウェル電磁気理論不信任派の筆者にとっては、さらに他の物理単位との整合性について、考察する必要があるのではないかと考えています。)
もう一つは、以前よく使われていたそうですが、硝酸銀の水溶液から電気分解で、毎秒1.11800mgの銀を分離するときの仮想電流の大きさによって定義するという方法もあるそうです。
例題のプログラムを実行した結果、1アンペアのとき、1時間あたり銀の析出量は4.025gですから、1秒あたりは約1.118mg程度となり、大体1アンペアの定義に近いことが分かります。
次に構造体に関するプログラムを例1-3とします。
/* 個人情報を印字する */
#include <stdio.h>
#日本語定義 構造体 "struct"
#日本語定義 整数型 "int"
#日本語定義 文字型 "char"
#日本語定義 型なし "void"
#日本語定義 印字 "printf"
#日本語定義 はじまり "main"
#日本語定義 個人情報型 "person"
#日本語定義 名前
#日本語定義 年齢
#日本語定義 性別
#日本語定義 生まれた年
#日本語定義 生まれた月
#日本語定義 生まれた日
構造体 個人情報型 {
文字型 名前[30];
整数型 年齢;
文字型 性別[4];
整数型 生まれた年;
整数型 生まれた月;
整数型 生まれた日;
};
#日本語定義 鈴木さんの記録
#日本語定義 山田さんの記録
型なし はじまり(型なし)
{
構造体 個人情報型 鈴木さんの記録 =
{"鈴木太郎",46,"男",1963,2,14};
構造体 個人情報型 山田さんの記録 =
{"山田花子",35,"男",1974,8,23};
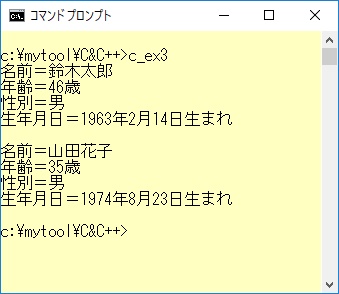
印字("名前=%s\n",鈴木さんの記録.名前);
印字("年齢=%d歳\n",鈴木さんの記録.年齢);
印字("性別=%s\n",鈴木さんの記録.性別);
印字("生年月日=%d年",鈴木さんの記録.生まれた年);
印字("%d月",鈴木さんの記録.生まれた月);
印字("%d日生まれ\n\n",鈴木さんの記録.生まれた日);
印字("名前=%s\n",山田さんの記録.名前);
印字("年齢=%d歳\n",山田さんの記録.年齢);
印字("性別=%s\n",山田さんの記録.性別);
印字("生年月日=%d年",山田さんの記録.生まれた年);
印字("%d月",山田さんの記録.生まれた月);
印字("%d日生まれ\n",山田さんの記録.生まれた日);
}
例1-3
やはり日本語が多用されているプログラムは大変読みやすいと思います。これは次のようなC言語のコードに展開されます。
/* 個人情報をデータベースとして印字する */
#include <stdio.h>
struct person {
char jp_str_0[30];
int jp_str_1;
char jp_str_2[4];
int jp_str_3;
int jp_str_4;
int jp_str_5;
};
void main(void)
{
struct person jp_str_6 =
{"鈴木太郎",46,"男",1963,2,14};
struct person jp_str_7 =
{"山田花子",35,"男",1974,8,23};
printf("名前=%s\n",jp_str_6.jp_str_0);
printf("年齢=%d歳\n",jp_str_6.jp_str_1);
printf("性別=%s\n",jp_str_6.jp_str_2);
printf("生年月日=%d年",jp_str_6.jp_str_3);
printf("%d月",jp_str_6.jp_str_4);
printf("%d日生まれ\n\n",jp_str_6.jp_str_5);
printf("名前=%s\n",jp_str_7.jp_str_0);
printf("年齢=%d歳\n",jp_str_7.jp_str_1);
printf("性別=%s\n",jp_str_7.jp_str_2);
printf("生年月日=%d年",jp_str_7.jp_str_3);
printf("%d月",jp_str_7.jp_str_4);
printf("%d日生まれ\n",jp_str_7.jp_str_5);
}
例1-3を展開したもの
ここで、日本語定義の部分についてですが、定義はプログラム中のどこに現われても構いませんが、同じ定義を二度以上使うことはできません。(この場合にはFLEXが警告を通知します)
例1-3の展開されたC言語プログラムを実行させた結果は以下のとおりです。
さらにポインタと配列を扱うプログラムを例1-4とします。
/* 引数をそのまま書き出す */
#include <stdio.h>
#日本語定義 整数型 "int"
#日本語定義 文字型 "char"
#日本語定義 型なし "void"
#日本語定義 印字 "printf"
#日本語定義 反復 "for"
#日本語定義 はじまり "main"
#日本語定義 もし "if"
#日本語定義 それ以外 "else"
#日本語定義 初期化なし " "
#日本語定義 の場合は、 " "
#日本語定義 を実行する " "
#日本語定義 引数の数 "argc"
#日本語定義 引数配列 "argv"
型なし はじまり(引数の数,引数配列)
整数型 引数の数;
文字型 *引数配列[];
{
反復 ( 初期化なし; 引数の数 > 1; --引数の数 ) {
印字("%s", *++引数配列);
もし( 引数の数 <= 2 )の場合は、印字("\n")を実行する;
それ以外の場合は、印字(" ")を実行する;
}
}
例1-4
C言語の規約により、mainの関数に渡されるパラメータは、引数の数と文字列としての引数配列があります(ANSI C規格では厳密には準拠していないということですが、ボーランド社の処理系ではmainの3番目の引数としてenvpもサポートしています)。 引数がない場合には引数の数は1となり、そのときの引数配列は[0]要素に実行プログラム名が格納されますが、引数が1つ以上ある場合には、引数の数は2以上で、引数の文字列は引数配列の[1]要素から順番に格納されます。
これは次のようなC言語のコードに展開されます。
/* 引数をそのまま書き出す */
#include <stdio.h>
void main(argc,argv)
int argc;
char *argv[];
{
for ( ; argc > 1; --argc ) {
printf("%s", *++argv);
if( argc <= 2 ) printf("\n") ;
else printf(" ") ;
}
}
例1-4を展開したもの
例1-4の実行プログラム名を「テスト」として次のような引数で実行させた場合の結果です。

これからC言語を勉強しようと思っておられる方々には、このような日本語の使い方を研究するよりも、まずはじめにCの文法を正確に理解し、ある程度使いこなせるようになってから日本語化を検討された方がよいと思います。それはC言語に慣れていないと、コンパイル時のエラーが頻発したときに対処ができなくなる恐れがあるからです。
今回ご紹介した方法は、まだまだ改良の余地はたくさんあるとは思いますが、興味のある方はご自分でも作って試してみるのもよいかもしれません。(コード量は大したことはありません) ただし、FLEXを十分使いこなすためには、やはりC言語をある程度理解していないと、なかなか難しい面があるのではないかと感じます。
また、何でも日本語化すればよいとは決して考えてはおりません。例えばループ変数などは、シンプルな英数字を付けた方がかえってC言語の流儀として読みやすいのではないかと思います。また、不適切な日本語をうっかり付けてしまうと、逆に読みやすさを損なうことも予想されます。しかしながらC言語で書かれたプログラムをある期間管理するという立場から見ますと、適当な日本語で記述することは日本語を母国語とする者にとって、とても有意義なことだと思います。
日常、C言語をよく利用されておられる方々の中にも、私と同じようにプログラムの中の変数名に日本語を使いたいとか、関数名に日本語が使えたらといいのにと考えている方もおられるのではないかと思いますが、処理系には手を加えずに、ちょっとした前処理を工夫することにより、C言語でも日本語を随分多めに記述することができるとのではないでしょうか。
次の例はC言語というわけではありませんが、最近の処理系はC言語の中でアセンブラ言語も比較的簡単に使用できるようになっているようです。この手法として、インラインアセンブラと呼ばれるC言語の中にアセンブラ言語を直接挿入する方法があります。
このインラインアセンブラを使ったプログラムを例1-5とします。
/* 文字列を繰り返し表示する */
#include <stdio.h>
#日本語定義 文字型 "char"
#日本語定義 型なし "void"
#日本語定義 短い整数型 "short int" /* 注SIレジスタは16ビットサイズ */
#日本語定義 はじまり "main"
#日本語定義 アセンブラ言語 "_asm"
#日本語定義 印字のための関数を呼ぶ "call printf"
#日本語定義 印字の後始末 "add esp,12"
#日本語定義 計算箱Aに値を入れる "mov eax"
#日本語定義 計算箱Aの中味をスタックへ積む "push eax"
#日本語定義 反復用箱に初期値=1を入れる "mov si,1"
#日本語定義 反復用箱の中味を1つ増加 "inc esi"
#日本語定義 相対番地計算 "offset"
#日本語定義 反復用箱と比べる "cmp si"
#日本語定義 中味が最大反復値以下であれば番地1へ分岐 "jl label_1"
#日本語定義 番地1 "label_1"
#日本語定義 最大反復値
#日本語定義 ;スタックポインタの値を適正化する ""
#日本語定義 最初の文字列
#日本語定義 2番目の文字列
#日本語定義 3番目の文字列
文字型 最初の文字列[] = "%s%s\n";
文字型 2番目の文字列[] = "世界の国から";
文字型 3番目の文字列[] = "こんにちは";
型なし はじまり(型なし)
{
短い整数型 最大反復値 = 10;
アセンブラ言語
{
反復用箱に初期値=1を入れる
番地1:
計算箱Aに値を入れる, 相対番地計算 3番目の文字列
計算箱Aの中味をスタックへ積む
計算箱Aに値を入れる, 相対番地計算 2番目の文字列
計算箱Aの中味をスタックへ積む
計算箱Aに値を入れる, 相対番地計算 最初の文字列
計算箱Aの中味をスタックへ積む
印字のための関数を呼ぶ
印字の後始末 ;スタックポインタの値を適正化する
反復用箱の中味を1つ増加
反復用箱と比べる, 最大反復値
中味が最大反復値以下であれば番地1へ分岐
}
}
例1-5
最近はC言語も汎用系だけに限らず、制御系などで使用される例も多くなっているようです。このインラインアセンブラが使用できる処理系であれば、日本語を多めに使用できるのではないかと考えられます。また、今回使用した処理系ではアセンブラ定義の中に直接アセンブラ流(;で始まる)コメントを書くとエラーが出るようでしたが(C流の/* コメント */は使えるようです)、日本語定義を使えば疑似コメントとして、文書内に残すことができるものと考えられます。
さらに、#日本語定義の行末にコメントを書くことができるようにしました。これは次のようなC言語のコードに展開されます。
/* 文字列を繰り返し表示する */
#include <stdio.h>
/* 注SIレジスタは16ビットサイズ */
char jp_str_1[] = "%s%s\n";
char jp_str_2[] = "世界の国から";
char jp_str_3[] = "こんにちは";
void main(void)
{
short int jp_str_0 = 10;
_asm
{
mov si,1
label_1:
mov eax, offset jp_str_3
push eax
mov eax, offset jp_str_2
push eax
mov eax, offset jp_str_1
push eax
call printf
add esp,12
inc esi
cmp si, jp_str_0
jl label_1
}
}
例1-5を展開したもの
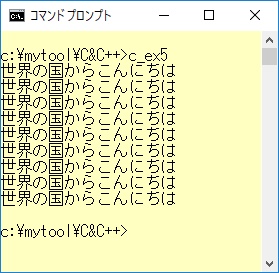
例1-5のプログラムを実行させたときの結果です。
日本語名の付け方については、C言語であらかじめ定義されている、int、float、char、struct、mainなどの予約語と呼ばれる識別子を日本語で置き換えた方がよいかどうかは、個人の好みや、そのときの判断によるところが大きいのではないかと考えられます。しかし、今回の用例では、全体的にコードリストが見やすいか見にくいかということではなく、なるべく日本語を多めに試用するということで、日本語で置き換える方針をとっています。
次の例は、初心者に分かりにくいといわれるポインタという概念について、日本語定義でどのくらい分かりにくさを軽減できるのかを試行してみました。
C言語のポインタは「*」(アスタリスク)という記号を用いて表していますが、この記号は算術演算子の掛け算という意味とポインタの両方の意味で使われています。また、ポインタの仲間でアドレスを表す「&」演算子というものがありますが、これもビットごとの論理積演算子と両方の意味を持たせてあります。
このポインタを使った変数の宣言文と、その変数を使う場合、またアドレス演算子との関係などがC言語の初心者にとっては頭が痛いのではないかと思います。そこで整理してみますと、まず通常の整数型の変数nanjaを宣言すると、以下のように記述されます。
int nanja;
この「nanja」という名前は、別の言い方をすると一つの記憶場所の番地であるとも言えます。しかし、「nanja」に対しての演算はあくまでも「nanja」番地ではなく、番地の中味に対して行われると考えられます。また、「nanja」番地自身を取り出すには「&nanja」と書くようにC言語では定められています。一方、ポインタを使用した場合には、次のように宣言されます。
int *monja;
これは「monja」番地という記憶場所の中味が、さらにまた別の記憶場所の番地を示すということになります(これは専門的には間接アドレッシングと呼ばれております)。そして、その間接的に示された番地の中味が整数型の値であると処理系に解釈されます。従って「monja」番地が示す間接的な番地の中味に何か整数の値を代入したい場合には、例えば次のような書き方をします。
*monja = 123;
このように宣言では「monja」が間接的な番地であるとするのに「*」を使っていますが、間接的な番地で示される中味の値を取り出したり、書き換えたりする場合にもやはり「*」の記号を使っています。
慣れた方には違和感がないのかもしれませんが、このあたりの記号の使い方が、どうもしっくりとなじまないのは筆者だけでしょうか。そこで今回の日本語定義では「*」については、間接的な「番地|」、間接的な番地の「中味|」というそれぞれ3文字の文字列に置き換えて使ってみました。
また、「&」については日本語定義では「参照|」という文字列に置き換えております。これはC++言語編にも出てくる参照型というものとの整合性を考えてみました。
次の例は現在の時刻を読み込んで、日本流の「刻」として表示するプログラムです。振り分けに「switch」文を使用し、「&」、「*」を日本語定義で「参照|」、「番地|」、「中味|」と置き換えてあります。
/* 現在の刻を表示する */
#include <stdio.h>
#include <dos.h>
#日本語定義 文字型 "char"
#日本語定義 型なし "void"
#日本語定義 整数型 "int"
#日本語定義 構造体 "struct"
#日本語定義 番地| "*"
#日本語定義 中味| "*"
#日本語定義 参照| "&"
#日本語定義 はじまり "main"
#日本語定義 通常終了 "return 0"
#日本語定義 振り分け "switch"
#日本語定義 場合分け "case"
#日本語定義 振り分け終了 "break"
#日本語定義 どれでもない "default"
#日本語定義 印字 "printf"
#日本語定義 現在の時間を読み出す "gettime"
#日本語定義 時間
"ti_hour"
#日本語定義 時分秒型 "time"
#日本語定義 子刻 "0"
#日本語定義 丑刻 "1"
#日本語定義 寅刻 "2"
#日本語定義 卯刻 "3"
#日本語定義 辰刻 "4"
#日本語定義 巳刻 "5"
#日本語定義 午刻 "6"
#日本語定義 未刻 "7"
#日本語定義 申刻 "8"
#日本語定義 酉刻 "9"
#日本語定義 戌刻 "10"
#日本語定義 亥刻 "11"
#日本語定義 今の刻
#日本語定義 時刻の集合
#日本語定義 文字列一
整数型 はじまり(型なし)
{
整数型 番地|今の刻;
文字型 文字列一[9] = {"今の刻は"};
構造体 時分秒型 番地|時刻の集合;
現在の時間を読み出す(時刻の集合);
中味|今の刻 = 時刻の集合 -> 時間 / 2 ;
印字("%s", 参照|文字列一[0]);
振り分け(中味|今の刻) {
場合分け 子刻: { 印字("子刻(ねのこく)です。\n"); }; 振り分け終了;
場合分け 丑刻: { 印字("丑刻(うしのこく)です。\n"); }; 振り分け終了;
場合分け 寅刻: { 印字("寅刻(とらのこく)です。\n"); }; 振り分け終了;
場合分け 卯刻: { 印字("卯刻(うのこく)です。\n"); }; 振り分け終了;
場合分け 辰刻: { 印字("辰刻(たつのこく)です。\n"); }; 振り分け終了;
場合分け 巳刻: { 印字("巳刻(みのこく)です。\n"); }; 振り分け終了;
場合分け 午刻: { 印字("午刻(うまのこく)です。\n"); }; 振り分け終了;
場合分け 未刻: { 印字("未刻(ひつじのこく)です。\n"); }; 振り分け終了;
場合分け 申刻: { 印字("申刻(さるのこく)です。\n"); }; 振り分け終了;
場合分け 酉刻: { 印字("酉刻(とりのこく)です。\n"); }; 振り分け終了;
場合分け 戌刻: { 印字("戌刻(いぬのこく)です。\n"); }; 振り分け終了;
場合分け 亥刻: { 印字("亥刻(いのこく)です。\n"); }; 振り分け終了;
どれでもない: { 印字("時計の異常です。\n"); }; 振り分け終了;
}
通常終了;
}
例1-6
例1─6のプログラムを展開すると以下のようになります。
/* 今の刻を表示する */
#include <stdio.h>
#include <dos.h>
int main(void)
{
int *jp_str_0;
char jp_str_2[9] = {"今の刻は"};
struct time *jp_str_1;
gettime(jp_str_1);
*jp_str_0 = jp_str_1 -> ti_hour / 2 ;
printf("%s", &jp_str_2[0]);
switch(*jp_str_0) {
case 0: { printf("子刻(ねのこく)です。\n"); }; break;
case 1: { printf("丑刻(うしのこく)です。\n"); }; break;
case 2: { printf("寅刻(とらのこく)です。\n"); }; break;
case 3: { printf("卯刻(うのこく)です。\n"); }; break;
case 4: { printf("辰刻(たつのこく)です。\n"); }; break;
case 5: { printf("巳刻(みのこく)です。\n"); }; break;
case 6: { printf("午刻(うまのこく)です。\n"); }; break;
case 7: { printf("未刻(ひつじのこく)です。\n"); }; break;
case 8: { printf("申刻(さるのこく)です。\n"); }; break;
case 9: { printf("酉刻(とりのこく)です。\n"); }; break;
case 10: { printf("戌刻(いぬのこく)です。\n"); }; break;
case 11: { printf("亥刻(いのこく)です。\n"); }; break;
default: { printf("時計の異常です。\n"); }; break;
}
return 0;
}
例1-6を展開したもの
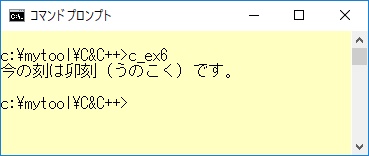
例1─6のプログラムを実行させたときの結果です。(これは7時00分ごろに実行しました)
話は変わりますが、その昔、筆者が学生時代に使用したC言語の処理系ではmain関数が値を返さないときのvoid型というものすらありませんでした。その後、C言語があちらこちらで使われるようになると、void型という値を返さない型が定義されるようになりました。
処理系によってはvoidと記述しないと警告が表示されるものもあるようです。今回の試行では、今のところmain関数自身が値を持って、その返された値をOSなどが利用するような例題は作っておりません。しかし、その必要があればもちろんそのように定義します。
従ってmainはvoid(型なし)として特に気にせずに今まで宣言しておりましたが、main関数をint型として宣言しておき、最後にreturn 0と一応書いて終了することがC言語通というような記述も散見されるようです。それが標準の(無難な?)書き方なのかどうかの議論はさておき、今回はそのように記述しております。
次の例は共用体を使用した例で32ビット整数、32ビット実数、64ビット実数について共用体で宣言した変数に値を代入したものです。
また、C言語の#define宣言のマクロ機能を利用して、printfを定義してあります。これと日本語定義を組み合わせて、さらにプログラムをすっきりと書いてみました。
/* 共用体を使用した例 */
#include <stdio.h>
#define lputs1(str) printf("%ld\n",str)
#define lputs2(str) printf("%3.20f\n",str)
#日本語定義 文字型 "char"
#日本語定義 型なし "void"
#日本語定義 整数型 "int"
#日本語定義 長い整数型 "long int"
#日本語定義 実数型 "float"
#日本語定義 長い実数型 "double"
#日本語定義 構造体 "struct"
#日本語定義 共用体 "union"
#日本語定義 型の定義 "typedef"
#日本語定義 はじまり "main"
#日本語定義 通常終了 "return 0"
#日本語定義 印字一 "lputs1"
#日本語定義 印字二 "lputs2"
#日本語定義 整数部分
#日本語定義 実数部分一
#日本語定義 実数部分二
#日本語定義 どちらでも共用できます型
#日本語定義 どちらでも
型の定義 共用体 {
長い整数型 整数部分;
実数型 実数部分一;
長い実数型 実数部分二;
} どちらでも共用できます型;
整数型 はじまり(型なし)
{
どちらでも共用できます型 どちらでも;
どちらでも.整数部分 = 20000;
印字一(どちらでも.整数部分);
どちらでも.実数部分一 = 3.14159265358979323846;
印字二(どちらでも.実数部分一);
どちらでも.実数部分二 = 3.14159265358979323846;
印字二(どちらでも.実数部分二);
通常終了;
}
例1-7
例1─7のプログラムを展開すると以下のようになります。
/* 共用体を使用した例 */
#include <stdio.h>
#define lputs1(str) printf("%ld\n",str)
#define lputs2(str) printf("%3.20f\n",str)
typedef union {
long int jp_str_0;
float jp_str_1;
double jp_str_2;
} jp_str_3;
int main(void)
{
jp_str_3 jp_str_4;
jp_str_4.jp_str_0 = 20000;
lputs1(jp_str_4.jp_str_0);
jp_str_4.jp_str_1 = 3.14159265358979323846;
lputs2(jp_str_4.jp_str_1);
jp_str_4.jp_str_2 = 3.14159265358979323846;
lputs2(jp_str_4.jp_str_2);
return 0;
}
例1-7を展開したもの
例1─7を実行すると以下のようになります。
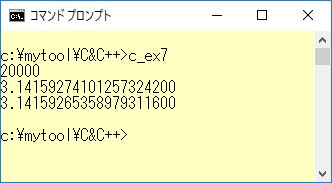
float型では有効桁数が7~8桁、double型では15~16桁ということですが、実行結果も大体このようになっていました。
πの計算
次の例題は外部宣言により、ほかのファイル内で定義された関数を呼び出すということをやってみます。この例として任意の桁数、πの値を計算するプログラムを書いてみます。これは「C─言語とプログラミング─」という本に出ているプログラムを参考にして日本語を多めに書いてみました。
基本的なアルゴリズムとしては古くから知られているマチン(イギリス人 J.Machin 1680-1752)の公式と呼ばれる式が使われております。ちなみに2019年3月、googleが約31兆4000億桁という世界記録を達成したとされるアルゴリズム(チャドノフスキーの公式)とはまた違うものです。 マチンの公式を用いたこのプログラムについて興味のある方は、機会があれば同書をご覧いただければ詳しく分かると思います。
今回のプログラムは二つに分かれており、一つははじまり(main)とマチンの公式を使うメイン関数の部分です。もう一つのファイルは、長い配列の加減除算などから成っております。それぞれ別々に翻訳(コンパイル)しておき、後から次のようなコマンドで結合します。
>bcc32 ファイル1.obj ファイル2.obj
この場合には以下のように入力します。

この結果、c_ex8-1.objとc_ex8-2.objが結合されて、c_ex_8-1.exeという実行可能ファイルが生成されます。外部宣言を行う場合には、呼び出す側と呼び出される側で、同じ名前として定義する必要があります。
/* マチンの公式を使用して、任意の桁数πの値を計算するプログラム */
#include <stdio.h>
#define lputs1 printf(" ")
#define lputs2 printf("\n ")
#日本語定義 型なし "void"
#日本語定義 整数型 "int"
#日本語定義 反復 "for"
#日本語定義 繰り返し "while"
#日本語定義 もし "if"
#日本語定義 それ以外 "else"
#日本語定義 外部定義 "extern"
#日本語定義 はじまり "main"
#日本語定義 通常終了 "return 0"
#日本語定義 戻る "return"
#日本語定義 印字 "printf"
#日本語定義 剰余計算 "%"
#日本語定義 印字一 "lputs1"
#日本語定義 印字二 "lputs2"
#日本語定義 基数 "10"
#日本語定義 配列の最大値 "3010"
#日本語定義 求める桁数 "3000"
#日本語定義 作業用配列一
#日本語定義 作業用配列二
#日本語定義 πの結果
#日本語定義 長い配列の割り算 "lng_dim_div"
#日本語定義 長い配列の加算 "lng_dim_add"
#日本語定義 長い配列の減算 "lng_dim_sub"
#日本語定義 非ゼロの位置を見つける "nzero_fnd"
#日本語定義 初期化 "init"
#日本語定義 反復数
外部定義 型なし 長い配列の減算( 整数型[], 整数型[], 整数型[] );
外部定義 型なし 長い配列の加算( 整数型[], 整数型[], 整数型[] );
外部定義 型なし 長い配列の割り算( 整数型[], 整数型[], 整数型, 整数型 );
外部定義 型なし 初期化( 整数型[], 整数型 );
外部定義 整数型 非ゼロの位置を見つける( 整数型[], 整数型 );
整数型 はじまり(型なし)
{
整数型 作業用配列一[配列の最大値+1],
作業用配列二[配列の最大値+1],
πの結果[配列の最大値+1];
整数型 反復数;
型なし マチンの逆正接演算( 整数型[], 整数型, 整数型 );
マチンの逆正接演算( 作業用配列一, 16, 5 );
マチンの逆正接演算( 作業用配列二, 4, 239 );
長い配列の減算( πの結果, 作業用配列一, 作業用配列二 );
印字( "%d.", πの結果[0] );
反復 ( 反復数 = 1; 反復数 <= 求める桁数; 反復数++ ) {
印字( "%d", πの結果[反復数] );
もし ( 反復数 剰余計算 10 == 0 ) 印字一;
もし ( 反復数 剰余計算 50 == 0 ) 印字二;
}
通常終了;
}
#日本語定義 マチンの逆正接演算
#日本語定義 かけ算定数
#日本語定義 級数定数
#日本語定義 正接変数
#日本語定義 配列引数
#日本語定義 非ゼロ位置
型なし マチンの逆正接演算( 配列引数, かけ算定数, 正接変数 )
整数型 配列引数[], かけ算定数, 正接変数;
{
整数型 作業用配列一[配列の最大値+1], 作業用配列二[配列の最大値+1];
整数型 非ゼロ位置, 級数定数 = 3;
初期化( 配列引数, 0 );
初期化( 作業用配列一, かけ算定数 );
長い配列の割り算( 作業用配列一, 作業用配列一, 正接変数, 0 );
非ゼロ位置 = 非ゼロの位置を見つける( 作業用配列一, 0 );
長い配列の加算( 配列引数, 配列引数, 作業用配列一 );
繰り返し( 非ゼロ位置 <= 配列の最大値 ) {
長い配列の割り算( 作業用配列一, 作業用配列一, 正接変数, 非ゼロ位置 );
長い配列の割り算( 作業用配列一, 作業用配列一, 正接変数, 非ゼロ位置 );
長い配列の割り算( 作業用配列二, 作業用配列一, 級数定数, 非ゼロ位置 );
もし ( 級数定数 剰余計算 4 == 1 )
長い配列の加算( 配列引数, 配列引数, 作業用配列二 );
それ以外
長い配列の減算( 配列引数, 配列引数, 作業用配列二 );
非ゼロ位置 = 非ゼロの位置を見つける( 作業用配列一, 非ゼロ位置 );
級数定数 += 2;
}
}
例1-8
外部宣言の本体であるもう一つのファイルの方は、無断掲載ということで怒られるといけませんので、割愛させていただきます。このような日本語定義を使用した外部関数の呼び出しについて、簡単な日本語定義の置き換えでも十分実用に耐えられるのではないかと考えております。
また、逆正接演算というのはアークタンジェント演算の意味です。例1─8のプログラムを展開すると以下のようになります。
/* マチンの公式を使用して、任意の桁数πの値を計算するプログラム
*/
#include <stdio.h>
#define lputs1 printf(" ")
#define lputs2 printf("\n ")
extern void lng_dim_sub( int[], int[], int[] );
extern void lng_dim_add( int[], int[], int[] );
extern void lng_dim_div( int[], int[], int, int );
extern void init( int[], int );
extern int nzero_fnd( int[], int );
int main(void)
{
int jp_str_0[3010+1],
jp_str_1[3010+1],
jp_str_2[3010+1];
int jp_str_3;
void jp_str_4( int[], int, int );
jp_str_4( jp_str_0, 16, 5 );
jp_str_4( jp_str_1, 4, 239 );
lng_dim_sub( jp_str_2, jp_str_0, jp_str_1 );
printf( "%d.", jp_str_2[0] );
for ( jp_str_3 = 1; jp_str_3 <= 3000; jp_str_3++ ) {
printf( "%d", jp_str_2[jp_str_3] );
if ( jp_str_3 % 10 == 0 ) lputs1;
if ( jp_str_3 % 50 == 0 ) lputs2;
}
return 0;
}
void jp_str_4( jp_str_8, jp_str_5, jp_str_7 )
int jp_str_8[], jp_str_5, jp_str_7;
{
int jp_str_0[3010+1], jp_str_1[3010+1];
int jp_str_9, jp_str_6 = 3;
init( jp_str_8, 0 );
init( jp_str_0, jp_str_5 );
lng_dim_div( jp_str_0, jp_str_0, jp_str_7, 0 );
jp_str_9 = nzero_fnd( jp_str_0, 0 );
lng_dim_add( jp_str_8, jp_str_8, jp_str_0 );
while( jp_str_9 <= 3010 ) {
lng_dim_div( jp_str_0, jp_str_0, jp_str_7, jp_str_9 );
lng_dim_div( jp_str_0, jp_str_0, jp_str_7, jp_str_9 );
lng_dim_div( jp_str_1, jp_str_0, jp_str_6, jp_str_9 );
if ( jp_str_6 % 4 == 1 )
lng_dim_add( jp_str_8, jp_str_8, jp_str_1 );
else
lng_dim_sub( jp_str_8, jp_str_8, jp_str_1 );
jp_str_9 = nzero_fnd( jp_str_0, jp_str_9 );
jp_str_6 += 2;
}
}
例1-8を展開したもの
2兆6999億9999万桁やギネス記録( 2011年)の10兆桁には遠く及びませんが、1949年フォンノイマン博士が2037桁を正しく求めたという記録がありました。実行はそれを少し上回る3,000桁で試してみました。 わずかパソコンで2、3秒待つと、以下のような結果が出てきました。
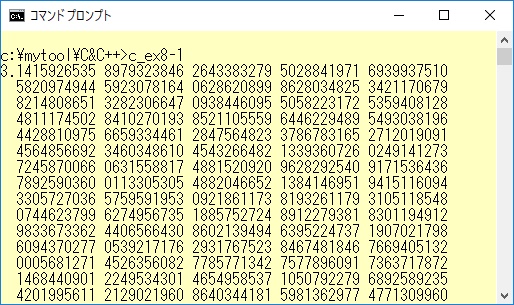
表示の関係上、スクリーンショットの画像で結果の全部を出すことができないので、結果を別ファイルに書き出したものを以下に示します。ほかのサイトで公開している数値と比べてみたところ間違いはないようです。
3.1415926535 8979323846 2643383279 5028841971 6939937510
5820974944 5923078164 0628620899 8628034825 3421170679
8214808651 3282306647 0938446095 5058223172 5359408128
4811174502 8410270193 8521105559 6446229489 5493038196
4428810975 6659334461 2847564823 3786783165 2712019091
4564856692 3460348610 4543266482 1339360726 0249141273
7245870066 0631558817 4881520920 9628292540 9171536436
7892590360 0113305305 4882046652 1384146951 9415116094
3305727036 5759591953 0921861173 8193261179 3105118548
0744623799 6274956735 1885752724 8912279381 8301194912
9833673362 4406566430 8602139494 6395224737 1907021798
6094370277 0539217176 2931767523 8467481846 7669405132
0005681271 4526356082 7785771342 7577896091 7363717872
1468440901 2249534301 4654958537 1050792279 6892589235
4201995611 2129021960 8640344181 5981362977 4771309960
5187072113 4999999837 2978049951 0597317328 1609631859
5024459455 3469083026 4252230825 3344685035 2619311881
7101000313 7838752886 5875332083 8142061717 7669147303
5982534904 2875546873 1159562863 8823537875 9375195778
1857780532 1712268066 1300192787 6611195909 2164201989
3809525720 1065485863 2788659361 5338182796 8230301952
0353018529 6899577362 2599413891 2497217752 8347913151
5574857242 4541506959 5082953311 6861727855 8890750983
8175463746 4939319255 0604009277 0167113900 9848824012
8583616035 6370766010 4710181942 9555961989 4676783744
9448255379 7747268471 0404753464 6208046684 2590694912
9331367702 8989152104 7521620569 6602405803 8150193511
2533824300 3558764024 7496473263 9141992726 0426992279
6782354781 6360093417 2164121992 4586315030 2861829745
5570674983 8505494588 5869269956 9092721079 7509302955
3211653449 8720275596 0236480665 4991198818 3479775356
6369807426 5425278625 5181841757 4672890977 7727938000
8164706001 6145249192 1732172147 7235014144 1973568548
1613611573 5255213347 5741849468 4385233239 0739414333
4547762416 8625189835 6948556209 9219222184 2725502542
5688767179 0494601653 4668049886 2723279178 6085784383
8279679766 8145410095 3883786360 9506800642 2512520511
7392984896 0841284886 2694560424 1965285022 2106611863
0674427862 2039194945 0471237137 8696095636 4371917287
4677646575 7396241389 0865832645 9958133904 7802759009
9465764078 9512694683 9835259570 9825822620 5224894077
2671947826 8482601476 9909026401 3639443745 5305068203
4962524517 4939965143 1429809190 6592509372 2169646151
5709858387 4105978859 5977297549 8930161753 9284681382
6868386894 2774155991 8559252459 5395943104 9972524680
8459872736 4469584865 3836736222 6260991246 0805124388
4390451244 1365497627 8079771569 1435997700 1296160894
4169486855 5848406353 4220722258 2848864815 8456028506
0168427394 5226746767 8895252138 5225499546 6672782398
6456596116 3548862305 7745649803 5593634568 1743241125
1507606947 9451096596 0940252288 7971089314 5669136867
2287489405 6010150330 8617928680 9208747609 1782493858
9009714909 6759852613 6554978189 3129784821 6829989487
2265880485 7564014270 4775551323 7964145152 3746234364
5428584447 9526586782 1051141354 7357395231 1342716610
2135969536 2314429524 8493718711 0145765403 5902799344
0374200731 0578539062 1983874478 0847848968 3321445713
8687519435 0643021845 3191048481 0053706146 8067491927
8191197939 9520614196 6342875444 0643745123 7181921799
9839101591 9561814675 1426912397 4894090718 6494231961
日本語カスタマイザーを利用してC言語を翻訳(コンパイル)するときに、プログラム中に文法的な問題があると警告メッセージやエラーメッセージが表示されます。このときにjp_str_*(*は数字)についてのエラー情報が出た場合、このjp_str_*とソースコード中の日本語文字列がどのように対応するのかが分からないとデバッグしにくいことが挙げられます。もっともエラーが出た行番号の情報は出力されますので、ソースコード上でどの行に問題があるのかは分かります。
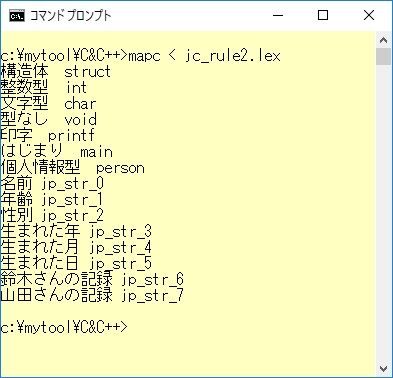
このようなデバッグ状況に対処する方法としては、日本語カスタマイザーが出力するjc_rule2.lexファイルが残っていますので、この中の規則記述部分を見ることによって、日本語文字列とそれに対応するjp_str_*がどれかということが分かります。多少手数はかかりますが、デバッグについて全く対処できないというわけではないと思います。
ここでは「mapc」というFLEXを用いた簡単なデバッグ用のツールを作ってみました。中味はjc_rule2.lexの規則記述部分だけを取り出して、表示するというものです。例題1-3において日本語カスタマイザーが出力したjc_rule2.lexを読み込ませた動作結果を以下に示します。このような簡単なツールを作ることで、日本語と実際に使われている予約語や変数を対応させることができるのではないかと思います。


参考図書
オートマトン・言語理論 本多波雄著 コロナ社 1972
UNIXプログラミング環境 Brian W.Kernighan Rob Pike 石田晴久監訳 アスキー出版局 1985
プログラミング言語C B.W. カーニハン D.M. リッチー 石田晴久訳 共立出版社 1981
UNIX 石田晴久著 共立出版社 1983
C─言語とプログラミング─ 米田信夫編 斎藤信男、武市正人、石畑清著 産業図書 1982
yacc/lex 五川女健治著 啓学出版社 1992
flex, version2.5 A Fast Scannar Generator ドキュメント University of California. Vern Paxsonほか多数のAuthor編著
高校化学Ⅰ 大饗 茂 大原出版 1978
新版物理Ⅰ 戸田盛和 大日本図書 1979
Cプリプロセッサー・パワー 林晴比古著 日本ソフトバンク出版社 1988
PIC16F8X データシート Microchip社